Ollama - lokalny asysten AI Obsidian-a
Grudzień 30, 2024 | #localhost , #ai , #obsidian
000100
001100
000110
Od chwili gdy świat poznał ChatGPT wszyscy oszaleli na punkcie sztucznej inteligencji (ang. Artificial intelligence - AI). Nieomal każdego dnia pojawiają się nowe narzędzia oparte o rozwiązania OpenAI, a konkurencja np. Google Gemini czy Claude.ai walczą o rynek. W zależności od branży i potrzeb różne rozwiązania zdobywają swoich zagorzałych fanów i tylko czasu brak aby to wszystko przetestować.
Wśród tych wszystkich cudownych projektów pojawiła się także Ollama Bez użycia chmury, zewnętrznych serwisów a nawet serwerów, na własnym komputerze możemy dzięki tej platformie uruchomić lokalną instancję sztucznej inteligencji, zasilić ją własnymi danymi i zacząć pracę nad aplikacją opartą o AI lub - jak w tym przypadku - ofiarować nieco inteligencji edytorowi notatek.
Nazwać Obsidian edytorem notatek to wielkie nieporozumienie. To wspaniała aplikacja, z której korzystają pisarze, nauczyciele, programiści i wiele innych grup zawodowych zakochanych w ogromnych możliwościach tego programu. Jego rozbudowane funkcjonalności są dodatkowo wzbogacone przez liczne oficjalne i nieoficjalne rozszerzenia w tym integrujące narzędzia AI. Integracja z ChatGPT wydaje się oczywista tyle, że wymaga to abonamentu i połączenia z internetem. Dlatego też ciekawą alternatywą są pluginy oferujące integrację z wyżej wspomnianą Ollamą.
Instalacja Ollama
Na początek należy odwiedzić minimalistyczną stronę projektu Ollama - https://ollama.com/download, wybrać swój system operacyjny oraz ściągnąć i zainstalować ją zgodnie z instrukcjami zaprezentowanymi na stronie.
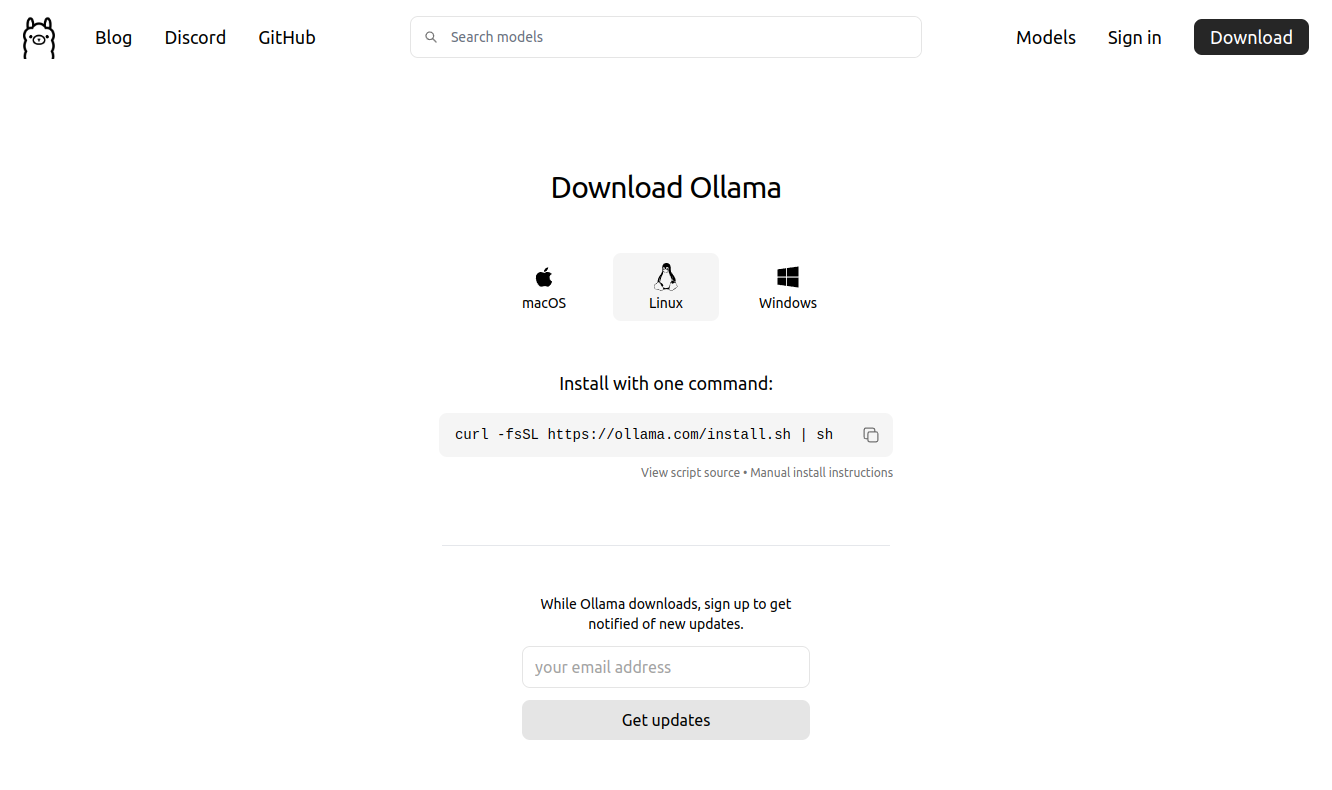
W przypadku systemu linux cały proces wykona się po uruchomieniu jednej instrukcji.
curl -fsSL https://ollama.com/install.sh | sh
>>> Installing ollama to /usr/local
[sudo] password for your.username:
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> Downloading Linux ROCm amd64 bundle
######################################################################## 100.0%
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
>>> AMD GPU ready.
Ollama poinformuje o możliwości użycia GPU albo ostrzeże, że wszystkie obliczenia będą wykonywane jedynie z użyciem CPU. Im mocniejszy komputer tym Ollama będzie działać sprawniej.
Wybór modelu językowego
Po instalacji platformy przyszedł czas na instalację modelu językowego. Z dostępnymi w danym momencie modelami językowymi można zapoznać się po wybraniu z górnego menu opcji "Models", który zaprowadzi do listy modeli posortowanych zgodnie z czasem ich ostatnich aktualizacji.
Ollama oferuje modele różnych firm (w tym m.in OpenAI, Meta (Facebook), Google), darmowe i płatne, przeznaczone do różnych celów (do pracy z tekstem, obrazem, wektorami i inne), o różnej ilości parametrów (1B, 3B, 8B, 70B i 405B) a tym samym różnej wielkości i wymaganiach.
Przy uruchamianiu modelu llama3.2 (3B) system zgłosił zapotrzebowanie na 3.5GB pamięci wewnętrznej, a przy llama3.3 (405B) już ponad 40GB RAM. Mniejsze modele to upraszczając mniejsze możliwości ale szybsze działanie przy zaangażowaniu mniejszej ilości zasobów. Tak więc wybór modelu nie sprowadza się jedynie do ceny i przeznaczenia ale też możliwości fizycznych sprzętu jakim dysponujemy. Więcej o modelach można poczytać m.in w artykule "Ollama – zbuduj chatGPT na własnym komputrze. Za darmo"
Instalacja modelu językowego i praca z nim z poziomu linii komend
Ja dla zobrazowania wybrałem niewielki model llama3.2 od Meta, który uruchomiłem poleceniem:
ollama run llama3.2
pulling manifest
pulling dde5aa3fc5ff... 100% ▕██████████████████████████████████████████▏ 2.0 GB
pulling 966de95ca8a6... 100% ▕██████████████████████████████████████████▏ 1.4 KB
pulling fcc5a6bec9da... 100% ▕██████████████████████████████████████████▏ 7.7 KB
pulling a70ff7e570d9... 100% ▕██████████████████████████████████████████▏ 6.0 KB
pulling 56bb8bd477a5... 100% ▕██████████████████████████████████████████▏ 96 B
pulling 34bb5ab01051... 100% ▕██████████████████████████████████████████▏ 561 B
verifying sha256 digest
writing manifest
success
>>> Send a message (/? for help)
Po ściągnięciu i zainstalowaniu modelu językowego uruchamiany jest też interaktywny chat, który z poziomu linii komend pozwala od razu wypróbować jego możliwości.
>>> Jaki jest wzór na pole tójkąta?
Wzór na pole trójkąta to:
P = (a × b × c) / 4, où a, b i c są długości ośców trójkąta.
Jeśli chcesz podać wzór dla trójkąta z jedną lub więcej wyrównanych odcinków, to musisz podać
powierzchnię i długość środkowej ościenia.
>>> Send a message (/? for help)
Aby zakończyć sesję chata należy wywołać komendę /bye.
Nie będę tu szczegółowo opowiadał o pracy z Ollama w wierszu poleceń (CLI) wspomnę tylko, że aby zobaczyć listę zainstalowanych modeli, odinstalować model itd. należy w pierwszej kolejności zaprzyjaźnić się z komendą ollama help, która zwraca listę opcji przypominających te z Dockera (choć Docker nie jest potrzebny do działania Ollama)
ollama help
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
Uruchamianie Ollama z Open WebUI
Open WebUI to przypominający ChataGPT interface graficzny w formie strony www do uruchamiania dużych modeli językowych (ang. Large Language Model - LLM) w tym Ollama.
Dokumentacja sugeruje szybki start z użyciem Dockera i podpowiada komendy jakich należy użyć do odpalenia na komputerze lokalnym lub też serwerze zdalnym oraz w zależności od posiadanej karty graficznej.
Najłatwiej odpalić WebUI w Dockerze z siecią w trybie gospodarza (--network host)
docker run -d -p 3000:8080 \
--network host \
-e OLLAMA_API_BASE_URL=http://localhost:11434 \
-v open-webui:/app/backend/data \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
Na próbę można tak zrobić, ale nie jest to zalecany sposób z uwagi na brak izolacji sieciowej, potencjalny konflikt portów i parę innych kwestii. Dlatego lepiej jest nie używać tego trybu, a dla większej wygody użyć ponadto docker compose.
docker-compose.yml
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
extra_hosts:
- "host.docker.internal:host-gateway"
ports:
- "3000:8080"
environment:
- OLLAMA_API_BASE_URL=host.docker.internal:11434
volumes:
- open-webui:/app/backend/data
restart: always
volumes:
open-webui:
Po uruchomieniu Dockera docker compose up, w przeglądarce pod adresem http://localhost:3000 powinien pojawić interfejs Open WebUI. Aby jednak zobaczyć poniższy widok należy założyć konto administratora, a następnie zalogować się na nie.
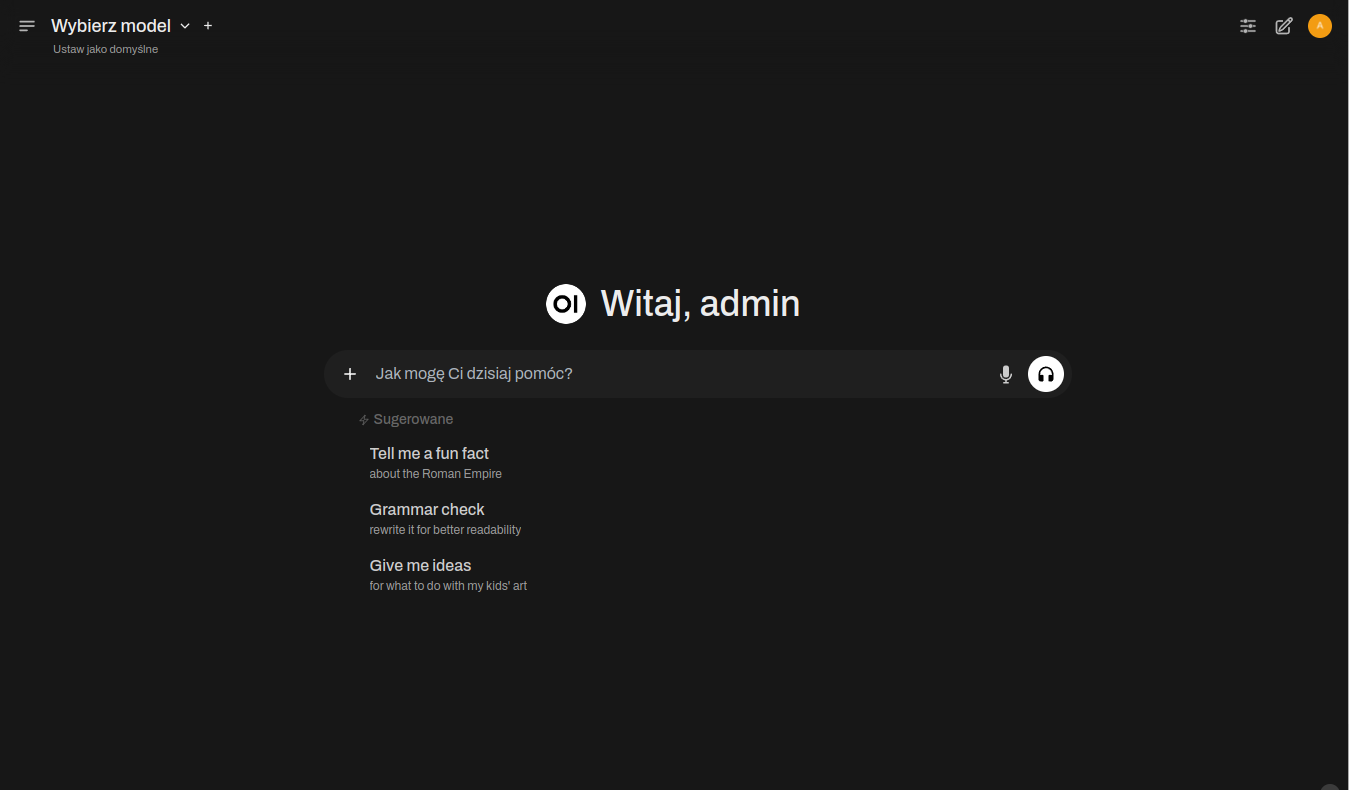
Przed zadaniem pierwszego pytania koniecznym jest wybranie modelu językowego. Należy go wybrać z listy w górnym lewym narożniku. Jeśli lista jest pusta przyczyną najpewniej jest nieuruchomiony serwis (systemd) ollama.
W moim przypadku serwis był uruchomiony o czym przekonałem się odpalając komendę:
sudo systemctl status ollama.service
Natomiast w logach kontenera dockerowego open-webui zauważyłem problem z połączeniem.
ERROR [open_webui.routers.ollama] Connection error: Cannot connect to host host.docker.internal:11434 ssl:default [Connect call failed ('172.17.0.1', 11434)]
Przyczyn takiego błędu może być kilka, ale w pierwszej kolejności należy sprawdzić:
1. Czy Ollama API nasłuchuje na interfejsie 0.0.0.0?
Żeby kontener mógł połączyć się z usługą Ollama API na hoście, usługa musi nasłuchiwać na interfejsie dostępnym dla kontenerów Docker. Najczęściej oznacza to nasłuchiwanie na 0.0.0.0 zamiast tylko na 127.0.0.1.
W celu sprawdzenia, na jakim adresie i porcie nasłuchuje Ollama API:
sudo ss -tuln | grep 11434
Oczekiwany wynik to
LISTEN 0 128 0.0.0.0:11434 0.0.0.0:*
albo
LISTEN 0 128 *:11434 *:*
Jeśli widać tylko 127.0.0.1:11434, oznacza to, że usługa jest dostępna tylko lokalnie na hoście.
Rozwiązanie
W takim wypadku należy (na Ubuntu)
Edytować plik konfiguracyjny serwisu
sudo vim /etc/systemd/system/ollama.service
albo - aby utworzyć plik override dla serwisu ollama
sudo systemctl edit ollama.service
i dodaj zmienną środowiskową
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Po dodaniu override lub wpisu do ollama.service, należy
- przeładować konfigurację serwisów, aby zmiany zostały uwzględnione,
- uruchomić ponownie serwis
ollama, aby nowe ustawienia zostały zastosowane, - upewnić się, że serwis działa poprawnie
sudo systemctl daemon-reload
sudo systemctl restart ollama.service
sudo systemctl status ollama.service
2. Czy port 11434 nie jest blokowany przez firewalla?
Jeśli Ollama API nasłuchuje na 0.0.0.0:11434, należy upewnić się, że port ten jest otwarty w zaporze sieciowej UFW.
Komenda sudo ufw status powinna dać nam informację czy zapora jest uruchomiona oraz jakie porty są otwarte.
Rozwiązanie
W razie problemów należy dodać regułę dla portu 11434/tcp i przeładować zaporę a następnie sprawdzić status serwisu
sudo ufw allow 11434/tcp
sudo ufw reload
sudo ufw status
Oczekiwany wynik po dodaniu reguły wygląda tak:
11434/tcp ALLOW Anywhere
3 Czy używana wersja Dockera obsługuje host-gateway
Funkcja host-gateway jest dostępna od Docker 20.10.0. Upewnij się, że używasz odpowiedniej wersji. docker --version
Po rozwiązaniu wszelkich ewentualnych problemów na liście w górnym lewym narożniku pojawią się dostępne modele językowe i możliwym się stanie zadawanie pytań.
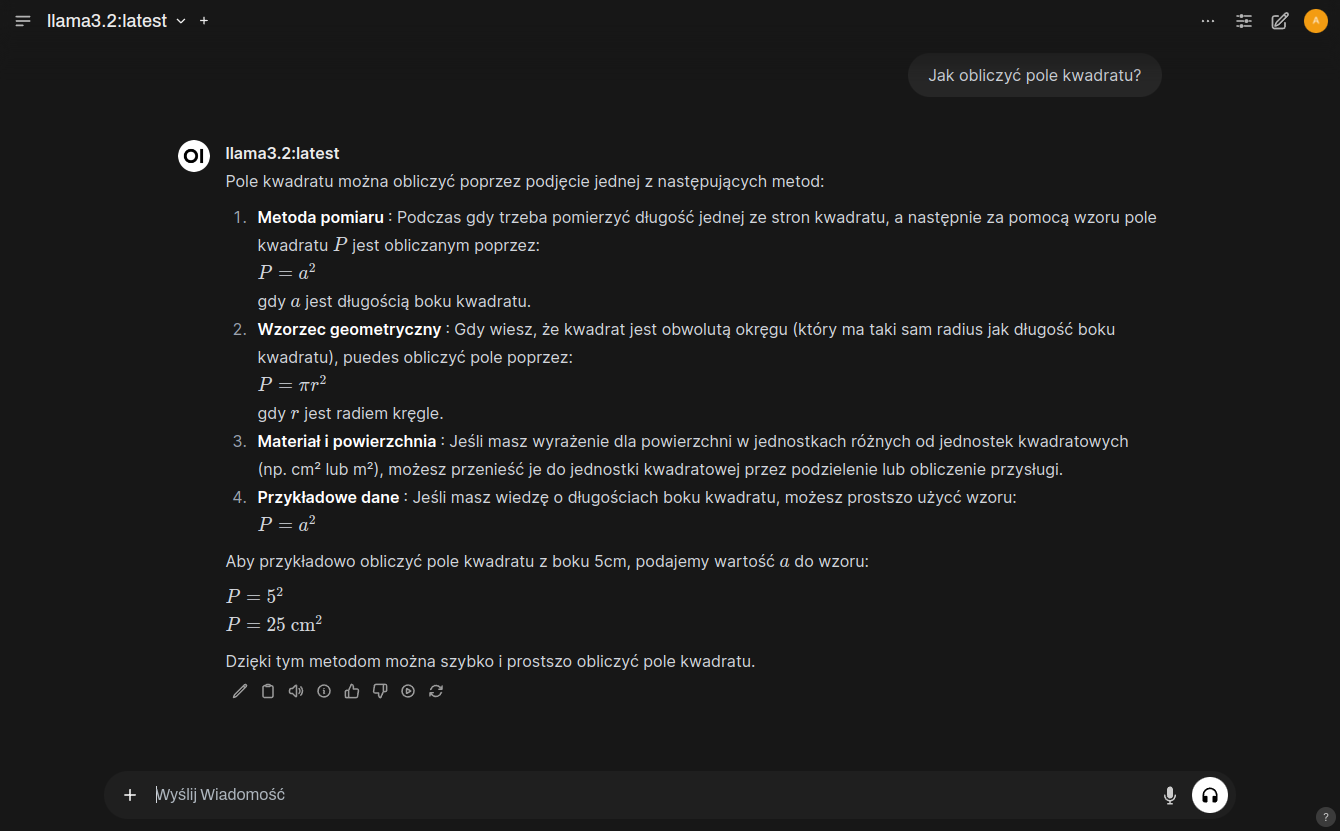
Integracja Ollama z Obsidian
Uruchamianie Open WebUI nie jest niezbędne w celu integracji Ollama z Obsidian ale upewnia nas, że wszystko jest w porządku. W końcu jednak przyszedł czas na zintegrowanie Ollama z Obsidianem, zasilenie modelu językowego danymi z notatek i użycie mocy AI do przyspieszenia pracy z edytorem.
Instalacja Smart Second Brain
Na początek należy zainstalować jeden z pluginów umożliwiających zintegrowanie Ollama z Obsidian-em.
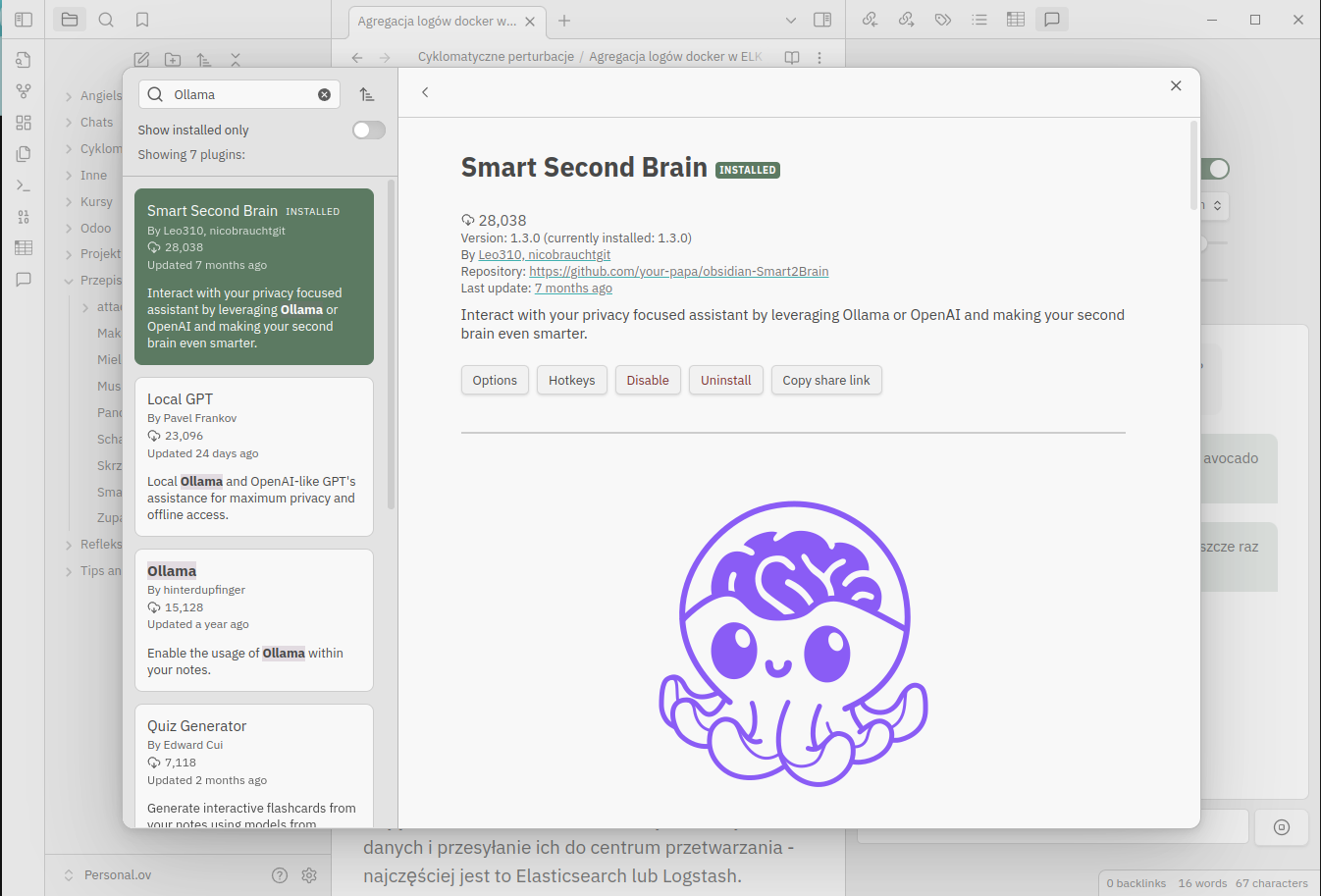
Zdecydowałem się na wypróbowanie Smart Second Brain ponieważ jest open-source, wygląda na prosty w użyciu, dopracowany i używany przez dużą liczbę użytkowników, a ponad to znalazłem szczegółową instrukcję instalacji ;).
Konfiguracja
Konfiguracja nie jest wymagająca
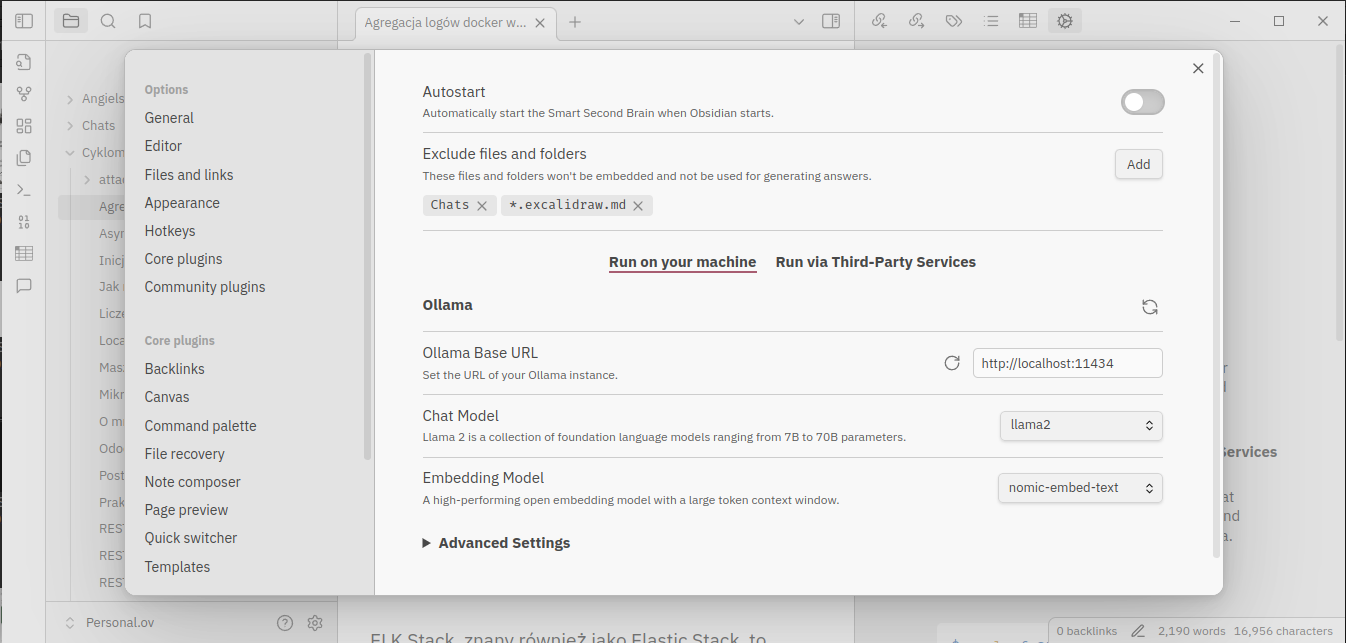
Można ustawić automatyczne uruchamianie wtyczki wraz ze startem Obsidian-a i wskazać pliki i foldery wykluczane z indeksowania. Wstępnie skonfigurowany jest też adres do Ollama API i model językowy dla chata, ale proponowany model może nie być tym, który jest już zainstalowany. Można tak zostawić i wtedy przed pierwszym użyciem wtyczka umożliwi pobranie i instalację tego modelu z poziomu Obsidiana. Zresztą podobnie jest z wymaganym modelem osadzania (ang. embedding model). Sugerowany model nomic-embed-text jest ok więc na początek w zupełności wystarczy.
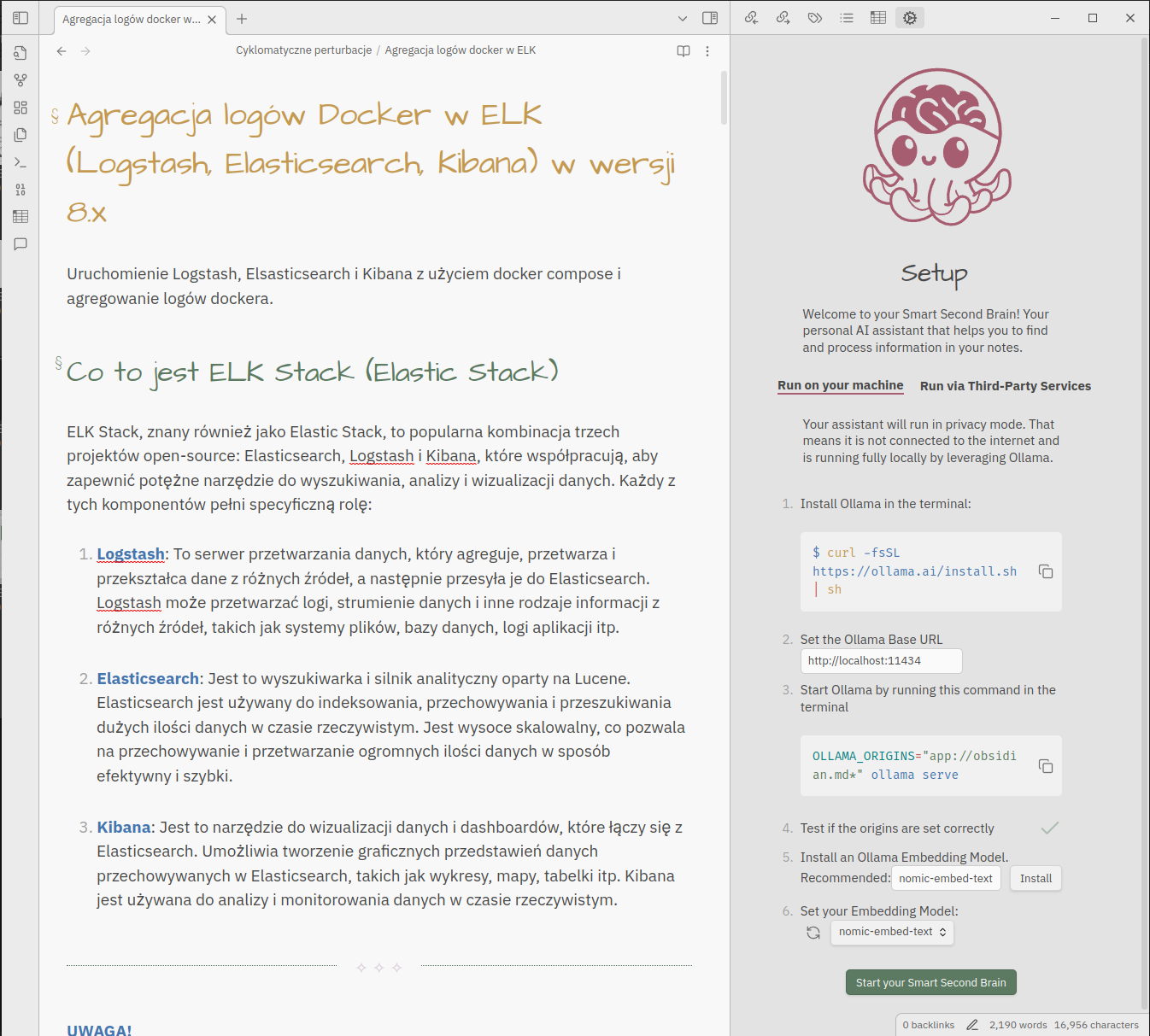
Przy pierwszym uruchomieniu (ikona chatu na pasku) plugin zaoferuję instrukcję instalacji Ollama (jeśli działa Open WebUI to możesz od razu przejść do punktu 4) oraz instalację brakujących modeli językowych wskazanych w ustawieniach. Po kliknięciu przycisku Start your Smart Second Brain rozpocznie się indeksowanie notatek.
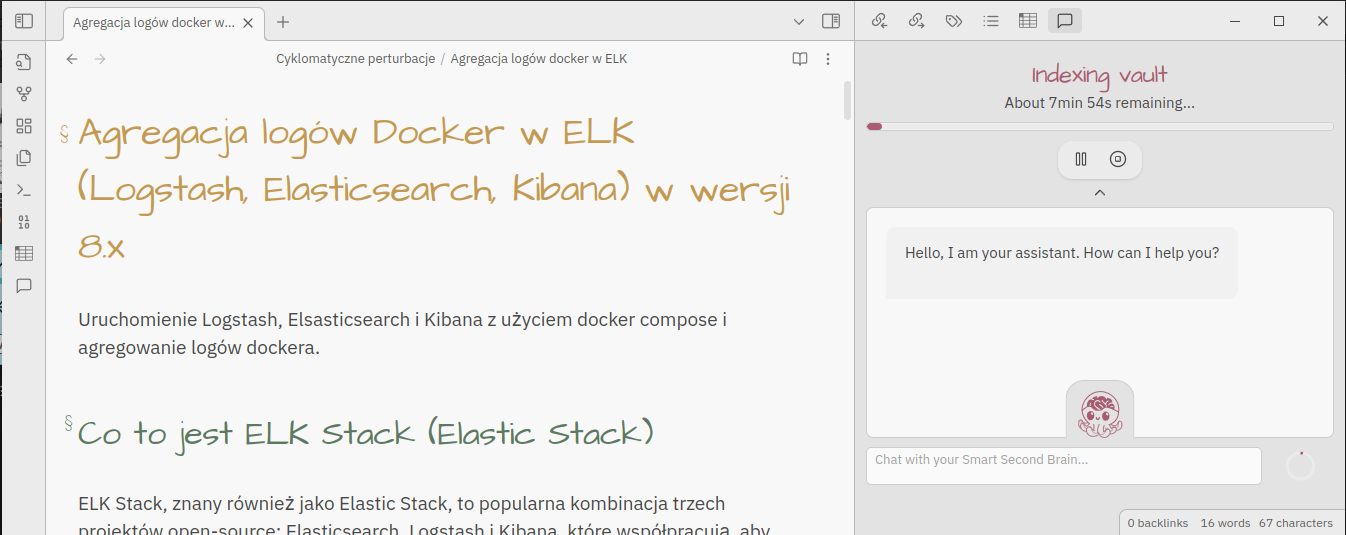
Jak długo będzie to trwało zależy od wielkości Twojego vault-a i możliwości maszyny na której to uruchamiasz. Po jego zakończeniu chat będzie gotowy do wypróbowania.
Użycie
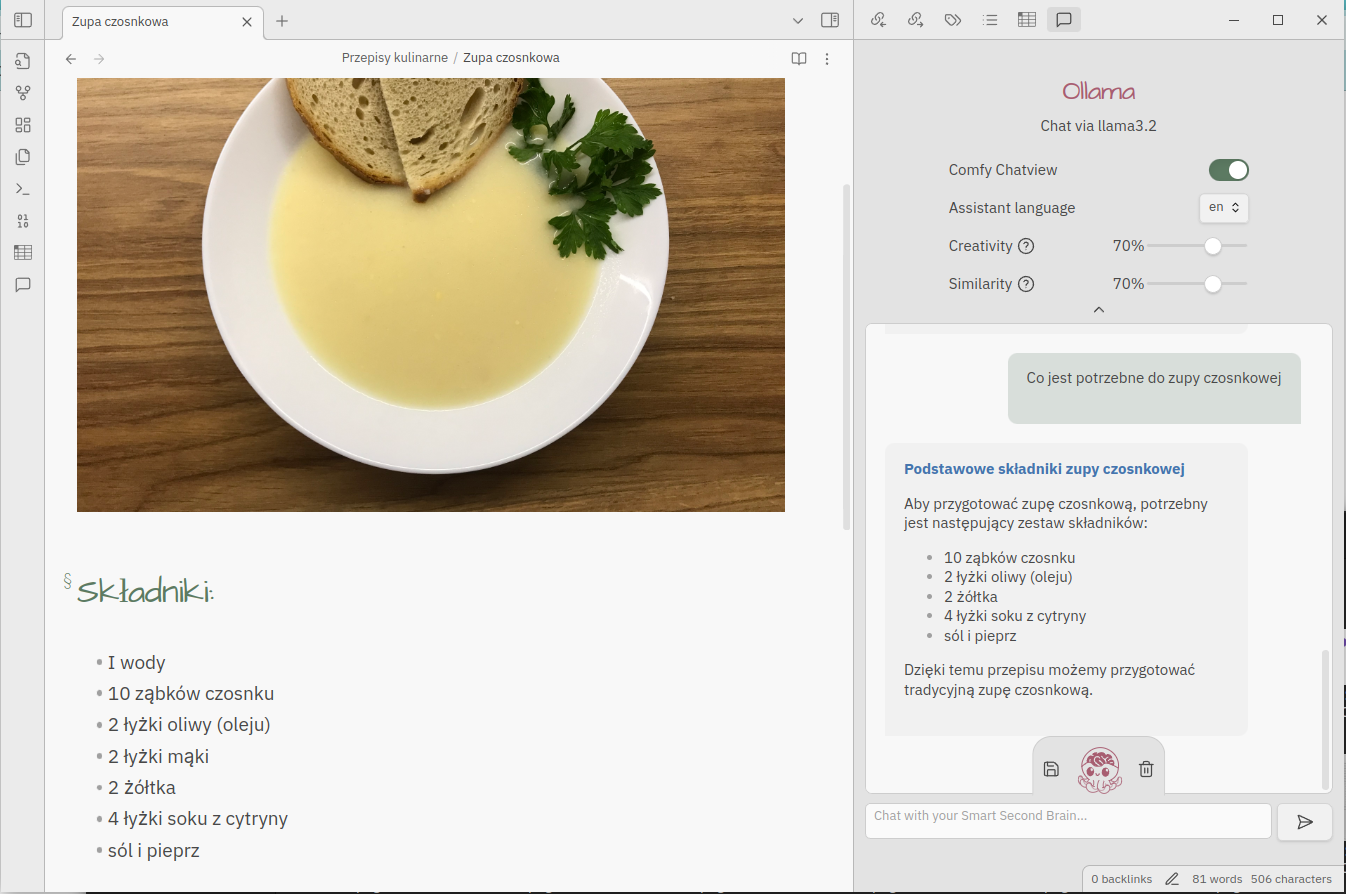
Jakość wyników jest pochodną użytego modelu językowego, ale też dwóch parametrów:
- Kreatywność (ang. Creativity): Dostosowuje poziom oryginalności wyników modelu do własnych preferencji.
- Podobieństwo (ang. Similarity): Stopień podobieństwa wyszukanych dokumentów do zapytania użytkownika.
W przypadku niezadowolenia z wyników można pobawić się suwakami i otrzymać zupełnie inny rezultat. Tworząc nową treść być może bardziej będzie zależeć nam na kreatywności, natomiast poszukując precyzyjnej odpowiedzi odpowiednie ustawienie similarity pozwoli na lepsze dopasowanie jej do pytania.
Należy pamiętać, że źródłem wiedzy nie są tylko nasze notatki ale też dane, na których model był trenowany dlatego przy zadawaniu pytania należy wziąć to pod uwagę.
Szybkość udzielanych odpowiedzi zależy w dużej mierze od możliwości sprzętowych więc nawet proste pytanie może zająć kilka minut zwłaszcza jeśli poprzedzone jest kilkoma wcześniejszymi pytaniami stanowiącymi jego kontekst.