LocalStack czyli bezpieczne bujanie w obłokach AWS
Styczeń 21, 2024 | #localhost , #cloud , #aws
011000
000100
100001
AWS LocalStack to narzędzie do emulowania chmury Amazon Web Services (AWS) na lokalnym komputerze i reklamowane jest jako niezbędne środowisko testowe każdego dewelopera, który w swojej pracy używa lub zamierza korzystać z usług AWS takich jak S3 (Simple Storage Service), Lambda, DynamoDB, API Gateway, SQS (Simple Queue Service), SNS (Simple Notification Service), i wielu innych - obecnie ponad 80.
LocalStack offline tylko dla profesjonalistów
Dedykowane jest zarówno studentom, początkującym programistom, jak i doświadczonym zespołom developerów. Świetnie nadaje się do nauki, ale też do rozwoju, testowania i debugowania aplikacji przed ich wdrożeniem w środowisku produkcyjnym. W wersji Enterprise LocalStack wspiera pracę w pełni offline co jest szczególnie przydatne w sytuacjach z ograniczonym dostępem do internetu lub gdy chce się uniknąć opóźnień związanych z siecią.
Ograniczenie kosztów AWS
Użycie LocalStack umożliwia ograniczenie kosztów związanych z korzystaniem z rzeczywistych usług AWS podczas fazy rozwoju i testowania. Niestety całkowite uniknięcie wydatków dotyczy jedynie najprostszych scenariuszy, gdyż w darmowej wersji Community funkcjonalność tego narzędzia jest ograniczona. Na stronie Feature Coverage można zapoznać się z listą symulowanych usług, poziomem ich emulacji oraz sprawdzić, które z funkcjonalności są dostępne za opłatą. Oznaczone są dopiskiem (PRO).
Teoretycznie można wypróbować LocalStack anonimowo - oczywiście tylko edycję Community. Wersja PRO i wyższe wymagają tokenu LOCALSTACK_AUTH_TOKEN, który generuje się po założeniu konta w serwisie localstack.cloud. Aby token zadziałał koniecznym jest powiązanie go z licencją, dostępną po wykupieniu subskrypcji.
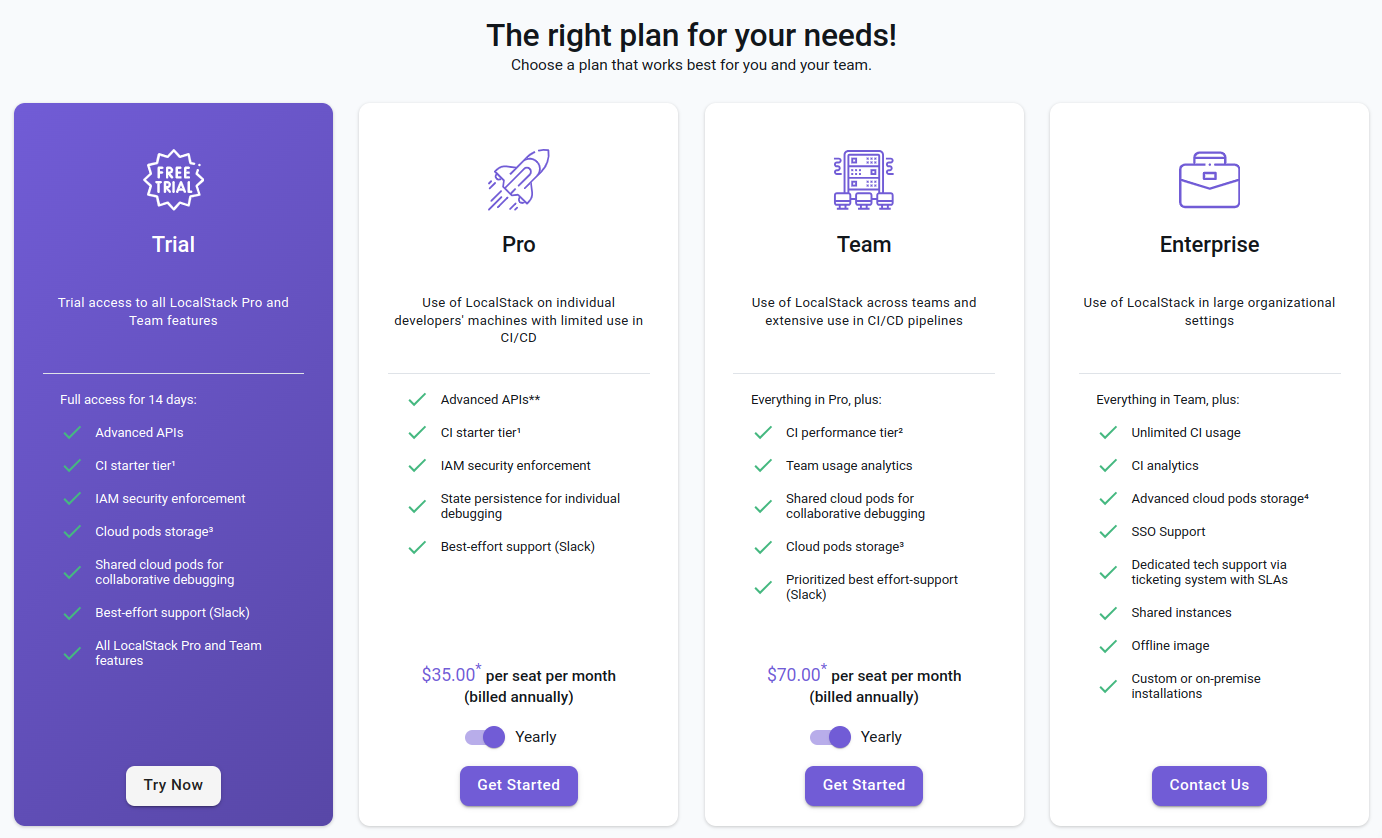 Z aktualnymi cenami można zapoznać się na stronie app.localstack.cloud/pricing. Subskrypcja trial pozwala wypróbować wszystkie dostępne usługi. Jej ważność upływa po 14 dniach więc nie nie ma co się spieszyć z jej aktywacją.
Z aktualnymi cenami można zapoznać się na stronie app.localstack.cloud/pricing. Subskrypcja trial pozwala wypróbować wszystkie dostępne usługi. Jej ważność upływa po 14 dniach więc nie nie ma co się spieszyć z jej aktywacją.
Nietrwałość zmian w darmowej wersji LocalStack
Niestety największym ograniczeniem darmowej edycji jest niemożność skorzystania z mechanizmu persystencji (trwałości). W praktyce oznacza to, że po zatrzymaniu LocalStack całe środowisko jest resetowane i wszystko co zostało utworzone w poprzedniej sesji przepada. W starszych wydaniach tego narzędzia można było użyć obrazu Docker-a localstack-light (obecnie po prostu localstack) i ustawić zmienną środowiskową PERSISTENCE=1 co sprawiało, że darmowa wersja była dla wielu programistów wystarczająca do prac deweloperskich i z chęcią używana z Docker Compose do rozwoju aplikacji Cloud Native. Nie trudno się domyślić przyczyn tej zmiany.
Mimo limitów narzucających efemeryczny charakter pracy najtańszej edycji LocalStack pozostaje ona wciąż użyteczna i wystarczająca do nauki wielu usług AWS, eksperymentów i testów integracji z zewnętrznymi narzędziami. Jeśli jednak oczekuje się trwałości wprowadzonych zmian jest się zmuszonym do pisania wniosku do swojego klienta lub pracodawcy o pokrycie kosztów subskrypcji. Warto jednak wcześniej upewnić się czy usługa, którą planuje się przetestować jest w pełni wspierana w zakresie persystencji bo może okazać się, że i tak niezbędne będą wydatki na rzeczywistą chmurę AWS.
Łatwość uruchomienia LocalStack
Dokumentacja informuje o możliwości uruchomienia lokalnego wydania chmury AWS na wielu różnych systemach operacyjnych i na różne sposoby, ale wszystkie one pod spodem używają kontenerów. Tak więc użycie wersji binarnej, modułu Pythona czy LocalStack Desktop i tak wiąże się z koniecznością odpalenia Docker-a.
Rekomendowany sposób instalacji LocalStack zgodny z instrukcję z sekcji Getting Started ze strony app.localstack.cloud lub dokumentacji - dla osób, które jeszcze się nie zarejestrowały - dla systemu Linux wygląda następująco.
Należy ściągnąć wersję binarną - różną w zależności od posiadanego procesora - najlepiej w najnowszej wersji - co można sprawdzić na jednej z wyżej podanych stron.
curl -Lo localstack-cli-3.0.2-linux-amd64-onefile.tar.gz \
https://github.com/localstack/localstack-cli/releases/download/v3.0.2/localstack-cli-3.0.2-linux-amd64-onefile.tar.gz
rozpakować ją
sudo tar xvzf localstack-cli-3.0.2-linux-*-onefile.tar.gz -C /usr/local/bin
i uruchomić
localstack start
__ _______ __ __
/ / ____ _________ _/ / ___// /_____ ______/ /__
/ / / __ \/ ___/ __ `/ /\__ \/ __/ __ `/ ___/ //_/
/ /___/ /_/ / /__/ /_/ / /___/ / /_/ /_/ / /__/ ,<
/_____/\____/\___/\__,_/_//____/\__/\__,_/\___/_/|_|
💻 LocalStack CLI 3.0.2
[23:51:18] starting LocalStack in Docker mode 🐳 localstack.py:495
──────────── LocalStack Runtime Log (press CTRL-C to quit) ─────────────
...
W przeciwieństwie do bezpośredniego użycia obrazu Dockera, wersja binarna instaluje także localstack-cli pozwalające nie tylko uruchomić LocalStack, ale mające też kilka innych interesujących funkcji np.
localstack config show
Po uruchomieniu warto sprawdzić czy wszystko jest ok. W przeglądarce albo z konsoli.
curl localhost:4566/_localstack/info | jq
{
"version": "3.0.3.dev:4ab8af96",
"edition": "community",
"is_license_activated": false,
...
}
Można też odpytać endpoint zwracający kondycję poszczególnych usług
curl localhost:4566/_localstack/health | jq
{
"services": {
"acm": "available",
"apigateway": "available",
"cloudformation": "available",
"cloudwatch": "available",
"config": "available",
"dynamodb": "available",
"dynamodbstreams": "available",
"ec2": "available",
"es": "available",
"events": "available",
...
},
"edition": "community",
"version": "3.0.3.dev"
}
Instalacja aws-cli i awscli-local
Z LocalStack pracuje się podobnie jak z prawdziwą chmurą za pośrednictwem AWS CLI.
Zarówno AWS CLI, jak i nakładka lokalizująca awscli-local są już zainstalowane wewnątrz uruchomionego kontenera co można sprawdzić dostając się do środka w trybie interaktywnym.
docker container ls # albo docker ps
docker exec -it d6e8c7a90cb4 /bin/sh
Docelowo wygodniej jest używać AWS CLI zainstalowane bezpośrednio na hoście, więc najlepiej od razu odwiedzić dokumentację aby sprawdzić jaka jest obecnie najnowsza wersja tego narzędzia i zainstalować ją zgodnie z podanymi tak instrukcjami:
# pobranie i rozpakowanie
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" \
-o "awscliv2.zip" && unzip awscliv2.zip
# instalacja
sudo ./aws/install --bin-dir `/usr/local/bin` --install-dir `/usr/local/aws-cli`
# sprzątanie
rm ./awscliv2.zip && rm -r ./aws
# weryfikacja
aws --version
Przed pierwszym użyciem należy wstępnie skonfigurować AWS CLI aby uniknąć komunikatu Unable to locate credentials. You can configure credentials by running "aws configure".
aws configure
AWS Access Key ID [None]: test
AWS Secret Access Key [None]: test
Default region name [None]: us-east-1
Default output format [None]:
Aby sprawdzić czy wszystko działa można odpytać LocalStack o listę wiader (buckets) w usłudze s3.
aws --endpoint-url=http://localhost:4566 s3api list-buckets
{
"Buckets": [],
"Owner": {
"DisplayName": "webfile",
"ID": "75aa57f09aa0c8caeab4f8c24e99d10f8e7faeebf76c078efc7c6caea54ba06a"
}
}
Otrzymany wynik wskazuje, że nie ma jeszcze żadnego wiadra.
Aby uniknąć dodawania do każdego żądania parametru --endpoint-url=http://localhost:4566 wskazującego na punkt końcowy LocalStack, warto pokusić się o użycie nakładki awscli-local.
sudo pip3 install awscli-local
awslocal --version
aws-cli/2.15.10 Python/3.11.6 Linux/6.2.0-39-generic exe/x86_64.ubuntu.22 prompt/off
Zgodnie z informacją ze strony awscli-local - przynajmniej na dzień pisania tego artykułu - deweloperzy nie przygotowali jeszcze wrappera przeznaczonego do aws-cli w wersji 2 w 100% z nią kompatybilnego, ale to co jest dostępne powinno zadziałać także z najnowszą wersją AWS CLI.
Sprawdźmy
awslocal s3api list-buckets
{
"Buckets": [],
"Owner": {
"DisplayName": "webfile",
"ID": "75aa57f09aa0c8caeab4f8c24e99d10f8e7faeebf76c078efc7c6caea54ba06a"
}
}
U mnie działa ;)
Pierwsze wiadro (bucket S3)
Tworzenie wiaderka w usłudze S3 jest banalnie proste.
awslocal s3api create-bucket --bucket testbucket
{
"Location": "/testbucket"
}
Uwaga
Do utworzenia wiaderka można użyć też polecenia z wysokopoziomowego zestawu poleceń AWS CLI awslocal s3 mb s3://testbucket, ale s3api daje większą kontrolę nad procesem tworzenia bucket-a. Powyżej użyto najprostszej składni nie mniej s3api pozwala także określić dodatkowe parametry, takie jak konfiguracja wiaderka, ACL (listy kontroli dostępu) oraz region, w którym wiaderko ma zostać utworzone.
Zestaw s3 to wysokopoziomowe API, które ułatwia realizację wielu operacji. W przypadku złożonych zadań realizuje je wywołując pod spodem szereg komend niskopoziomowych API. Nie ma prostego sposobu sprawdzenia co jest odpalane w tle i może to czasem być powodem trudności w diagnozowaniu problemu.
Powodzenie powyższej instrukcji można sprawdzić odpytując S3 o listę wiaderek
awslocal s3api list-buckets
{
"Buckets": [
{
"Name": "testbucket",
"CreationDate": "2024-01-17T12:35:20.000Z"
}
],
"Owner": {
"DisplayName": "webfile",
"ID": "75aa57f09aa0c8caeab4f8c24e99d10f8e7faeebf76c078efc7c6caea54ba06a"
}
}
Kolejną opcją jest odpytanie odpowiedniego punktu końcowego
https://testbucket.s3.localhost.localstack.cloud:4566/
# albo http://localhost:4566/testbucket
<ListBucketResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<IsTruncated>false</IsTruncated>
<Marker/>
<Name>testbucket</Name>
<Prefix/>
<MaxKeys>1000</MaxKeys>
</ListBucketResult>
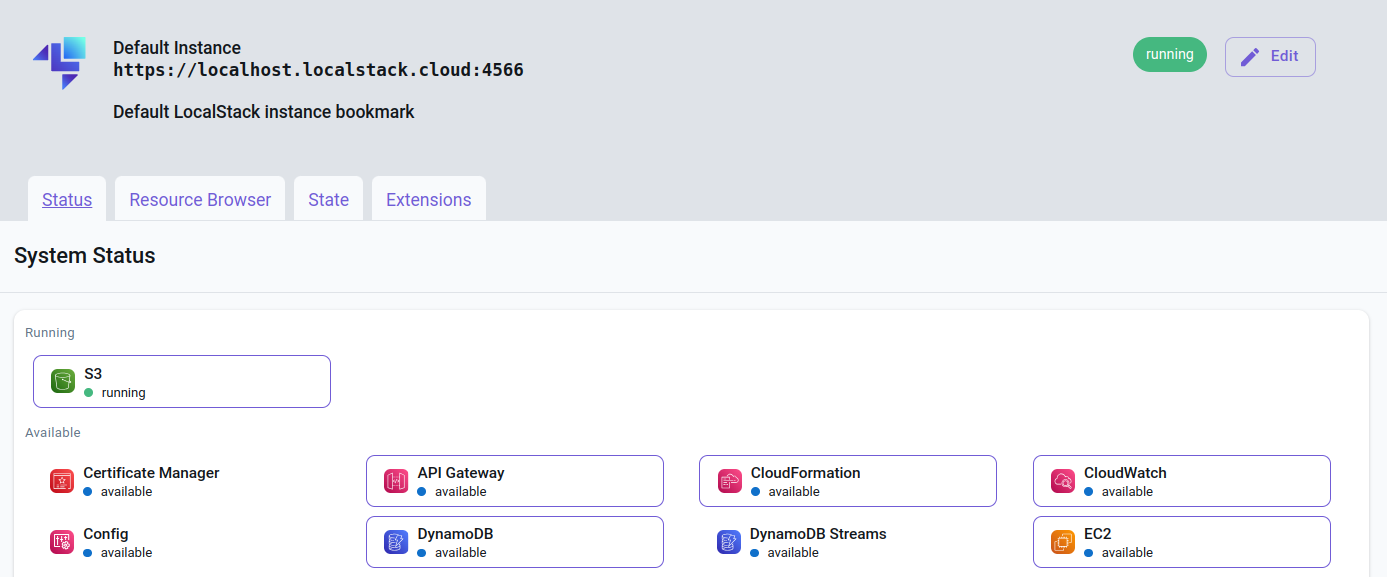
Można też sprawdzić status na stronie app.localstack.cloud/inst/default/status (Menu: LocalStack Instances -> Default Instance -> Status). Interaktywny panel jest jednym z benefitów jakie daje rejestracja w serwisie localstack.cloud.
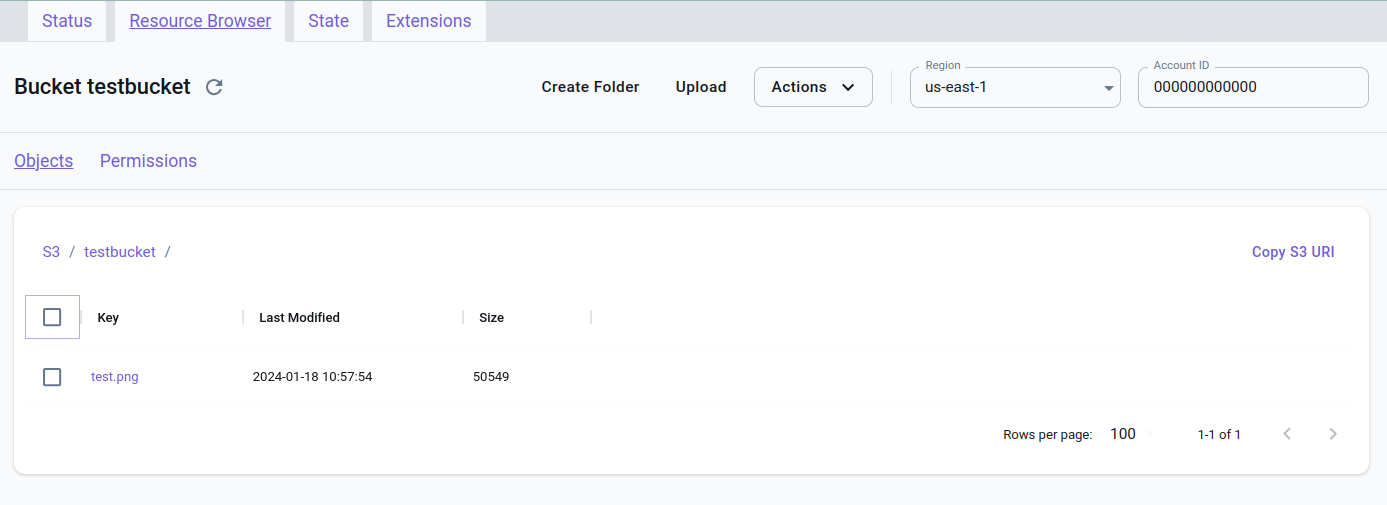
Po dodaniu obrazka do wiaderka ...
awslocal s3 cp test.png s3://testbucket
... lista obiektów wiaderka zawiera jedną pozycję. Pokazane są najważniejsze informacje.
awslocal s3api list-objects --bucket testbucket
{
"Contents": [
{
"Key": "test.png",
"LastModified": "2024-01-18T09:57:54+00:00",
"ETag": "\"4f4859a673e6b25e5f8811cfca26e174\"",
"Size": 50549,
"StorageClass": "STANDARD",
"Owner": {
"DisplayName": "webfile",
"ID": "75aa57f09aa0c8caeab4f8c24e99d10f8e7faeebf76c078efc7c6caea54ba06a"
}
}
],
"RequestCharged": null
}
Aktualizacja informacji na stronie app.localstack.cloud/inst/default/resources/s3/testbucket może wymagać chwili.
Użycie LocalStack w skrypcie Python
Integracja z usługą S3 dostarczaną przez LocalStack w miejsce rzeczywistej chmury AWS w skrypcie Python wygląda niemal identycznie. Jedyne o co trzeba zadbać to dodanie parametru z punktem końcowym wskazującym na środowisko lokalne.
import boto3
boto3.client("s3", endpoint_url="http://localhost:4566")
Przykładowy skrypt wysyłający plik test.txt do S3 mógłby wyglądać tak.
import boto3
s3_client = boto3.client("s3", endpoint_url="http://localhost:4566")
bucket_name = "testbucket"
file_path = "./test.txt"
s3_file_name = "renamed.txt"
with open(file_path, "rb") as file:
s3_client.upload_fileobj(file, bucket_name, s3_file_name)
print(f"The file {file_path} was uploaded to the {bucket_name} as {s3_file_name}.")
Uwaga
Jeśli miałeś już do czynienia z wierszem poleceń AWS to być może zastanawiasz się czy mógłbyś - zamiast dodawać parametr endpoint_url="http://localhost:4566" - po prostu skonfigurować sobie profil "lokalny" i obsłużyć to bardziej elegancko.
import boto3
session = boto3.Session(profile_name='local-profil')
s3_client = session.client('s3')
Niestety, parametr endpoint_url nie może być dodany bezpośrednio do profilu w pliku konfiguracyjnym AWS CLI. Pliki konfiguracyjne AWS CLI (~/.aws/config i ~/.aws/credentials) służą głównie do przechowywania informacji o poświadczeniach i ustawieniach regionalnych, a nie do konfiguracji szczegółowych ustawień klienta, takich jak niestandardowe adresy URL punktów końcowych.
Kolejny przykład prezentuje jak pobrać plik z usługi S3, zmodyfikować go w pamięci bez zapisywania na dysku i wysłać z powrotem do wiaderka pod tą samą nazwą.
import boto3
import io
s3_client = boto3.client("s3", endpoint_url="http://localhost:4566")
bucket_name = 'testbucket'
file_name = 'renamed.txt'
# Pobieranie pliku z S3 do obiektu w pamięci
file_obj = io.BytesIO()
s3_client.download_fileobj(bucket_name, file_name, file_obj)
file_obj.seek(0) # Przewijanie do początku pliku
# Odczytanie zawartości pliku i dodanie "Lorem ipsum"
content = file_obj.read().decode('utf-8') # Zakładając, że plik jest w kodowaniu UTF-8
content += "\nLorem ipsum" # Dodawanie tekstu
# Przygotowanie zmodyfikowanej zawartości do wysłania
file_obj = io.BytesIO(content.encode('utf-8')) # Ponowne konwertowanie tekstu na bajty
# Wysyłanie zmodyfikowanego pliku z powrotem na S3 pod tą samą nazwą
s3_client.upload_fileobj(file_obj, bucket_name, file_name)
Pobranie pliku z S3 i zapisanie go pod nazwą test2.txt pozwala porównać go do pierwotnie wysłanego pliku test.txt
awslocal s3 cp s3://testbucket/renamed.txt ./test2.txt
Pobieranie pliku z S3 w celu jego modyfikacji i ponowne wysyłanie w to samo miejsce jest proste ale istnieje lepsze rozwiązanie.
Wdrażanie funkcji Lambda
Zaprezentowana poniżej minimalistyczna funkcja lambda tworząca miniatury przesłanych na S3 obrazków w formacie png jest prostym przykładem aplikacji bezserwerowej (serwesless). Jest łatwa do zrozumienia i możesz ją potraktować jako wstęp do bardziej zaawansowanego wdrożenia zaprezentowanego w artykule "Szybki start" (Quickstart) z oficjalnej dokumentacji, gdzie użyta została rozbudowana aplikacja webowa a cała funkcjonalność opiera się na kilku wzajemnie uzupełniających się usługach AWS.
Aby użyć jakiejkolwiek funkcji Lambda za pośrednictwem AWS SDK trzeba wykonać kilka kroków.
- Napisać funkcję, która będzie realizować zakładane zadanie
- Przygotować pakiet wdrożeniowy
- Wdrożyć funkcję w systemie chmurowym
- Przetestować działanie funkcji
- Opcjonalnie - jeśli funkcja ma reagować na jakieś zdarzenie - zdefiniować trigger, który zareaguje na wystąpienie określonego zdarzenia i wywoła funkcję
Przykładowa funkcja tworząca miniaturę pliku graficznego w formacie png i zapisująca ją w tym samym wiaderku (buckecie) została zdefiniowana w pliku lambda_function.py
Tworzenie funkcji Lambda
import boto3
from PIL import Image
import io
s3_client = boto3.client("s3")
def validate_file_name(image_path):
'''Check if file do not have thumb_prefix and is png'''
if image_path.startswith("thumb_"):
raise ValueError("The image is already resized")
if not image_path.endswith(".png"):
raise ValueError("The file is not png")
def resize_image(image_path, resized_path, size=(128, 128)):
with Image.open(image_path) as image:
image.thumbnail(size)
image.save(resized_path)
def lambda_handler(event, context):
results = []
for record in event["Records"]:
bucket = record["s3"]["bucket"]["name"]
file_name = record["s3"]["object"]["key"]
try:
validate_file_name(file_name)
except ValueError as e:
results.append("File {} was not omitted. {}".format(file_name, e))
continue
download_path = "/tmp/{}".format(file_name)
upload_path = "/tmp/thumb_{}".format(file_name)
s3_client.download_file(bucket, file_name, download_path)
resize_image(download_path, upload_path)
s3_client.upload_file(upload_path, bucket, "thumb_{}".format(file_name))
results.append("Created thumbnail thumb_{}".format(file_name))
return results
Warto zwrócić uwagę na kilka kwestii
- Rozwiązanie projektowane jest do użycia wewnątrz środowiska AWS, a co za tym idzie inicjacja klienta
boto3nie wymaga podania punktu końcowego wskazującego na LocalStacks3_client = boto3.client('s3') - Funkcja walidująca nazwę pliku
validate_file_nameprzepuszcza tylko pliki w formaciepngzgłaszając wyjątek w przypadku, każdego innego formatu. Zapobiega to wystąpieniu błędów w przypadku przesłania np. plików tekstowych czy innych, dla których nie ma sensu tworzenie miniatur. Oczywiście nie zabezpiecza to przed plikami, które np. mają nadane błędne rozszerzenie. Ograniczenie od tylko jednego formatu plik graficznego zostało przyjęte w celu uproszczenia przykładu - Bardzo ważny jest drugi warunek funkcji walidującej, który sprawdza istnienie prefiksu
thumb_. Prefix ten jest nadawany każdej miniaturce wygenerowanej na podstawie oryginalnego pliku. Funkcja sprawdza czy nazwa przesłanego do niej pliku ma już taki prefix co zapobiegnie tworzeniu miniatur z miniatur. Ma to niebagatelne znaczenie w przypadku zdefiniowania trigger-a, który będzie wywoływał funkcję lambda w reakcji na zdarzenie pojawienia się nowego pliku w wiaderku. Ponieważlambda_handlerzapisuje przeskalowany plik w tym samym wiaderku co oryginał utworzenie miniatury powoduje ponowne wystąpienie zdarzenia i ponowne wywołanie funkcji lambda. W efekcie mogłoby dojść do rekurencji. Z oryginału powstała by miniatura, z miniatury kolejna miniatura itd. lambda_handlerczyli de facto instrukcja wywoływana w trakcie odpalania funkcji lambda mogłaby nic nie zwracać. Zdefiniowanie zmiennej results i zapisywanie w niej komunikatów zostało zaimplementowane tylko i wyłącznie na potrzeby niżej zaprezentowanego testu.
Przygotowywanie pakietu wdrożeniowego
Aby stworzyć pakiet wdrożeniowy dla funkcji Lambda w języku Python należy wykonać kilka kroków
Skrypt zawierający funkcję Lamda najprawdopodobniej wymaga jakichś zależności. W podanym wyżej przykładzie niezbędne jest zapewnienie dostępu do modułów boto3 i Pillow (nowsza wersja PIL)
W tym celu nawygodniej utworzyć środowisko wirtualne Python i zainstalować w nim wymagane pakiety
mkdir .venv
pipenv install boto3 Pillow
Należy utworzyć folder na pakiet wdrożeniowy np. lambda_package, przekopiować, do niego lambda_function.py oraz zależności (zawartość katalogu site-packages lub dist-packages w zależności od systemu i faktu użycia środowiska wirtualnego) i spakować wszystko w celu łatwiejszej dystrybucji.
mkdir ./lambda_package
cp -r .venv/lib/python3.10/site-packages/* ./lambda_package/
cp lambda_function.py ./lambda_package/
cd ./lambda_package/ && zip -r ../lambda_package.zip .
Uwaga
W razie trudności ze zlokalizowaniem zależności, ich lokalizację można poznać dzięki instrukcji
import site; print(site.getsitepackages()).Należy upewnić się, że ścieżka do zależności w pakiecie ZIP jest prawidłowa. AWS Lambda musi być w stanie znaleźć i zaimportować te zależności podczas wykonywania funkcji.
Nie bez znaczenia jest też wielkość pakietu. AWS Lambda ma ograniczenia co do rozmiaru pakietu wdrożeniowego.
Wdrożenie funkcji Lambda
Skrypt zawierający kod, który będzie uruchamiany przez funkcję Lambda, oraz wszystkie zależności zostaną następnie wysłane do AWS lub jak w tym wypadku do LocalStack.
Wdrożyć funkcję Lambda można za pomocą AWS CLI lub AWS Management Console.
awslocal lambda create-function \
--function-name my-resize-function \
--zip-file fileb://lambda_package.zip \
--handler lambda_function.lambda_handler \
--runtime python3.10 \
--role arn:aws:iam::123456789012:role/lambda-ex
--function-name: nazwa funkcji Lambda.--zip-file: ścieżka do pakietu wdrożeniowego (w typ przypadku zostało założone, że polecenie uruchamiane jest z poziomu katalogu w którym znajduje się pakiet wdrożeniowy).--handler: ścieżka do funkcji obsługi w pakiecie. W tym przykładzie jest tolambda_function.lambda_handler, co oznacza, że funkcjalambda_handlerjest zlokalizowana w plikulambda_function.py. Będzie ona używana jako funkcja obsługi.--runtime: środowisko uruchomieniowe dla funkcji.--role: ARN roli IAM - można użyć fikcyjnej wartości, ponieważ LocalStack nie symuluje rzeczywistego zarządzania uprawnieniami IAM w taki sam sposób, jak robi to AWS.
Uwaga
Funkcja Lambda musi mieć uprawnienia do odczytu z wiadra S3 i zapisu do niego. W rzeczywistym AWS koniecznym byłoby utworzenie odpowiedniej roli IAM i przydzielenie jej do funkcji lambda. W LocalStack można obecnie zarządzać w sposób szczegółowy uprawnieniami, ale w przypadku braku niestandardowej konfiguracji poświadczeń, wszystkie żądania do LocalStack są uruchamiane z poziomu administratora root.
Możliwa jest aktualizacja kodu handlera funkcji Lambda bez konieczności jest wcześniejszego usuwania.
aws lambda update-function-code \
--function-name my-resize-function
--zip-file fileb://lambda_package.zip
Jest to o tyle wygodne, że rezygnacja z funkcji Lambda wiąże się z koniecznością wcześniejszego usunięcia zależności z nią związanych np. triggerów takich jak Amazon S3, Amazon SNS, Amazon DynamoDB Streams, czy inne usługi AWS, które automatycznie wywołują funkcję . Powinny one zostać usunięte lub odłączone, aby uniknąć błędów lub nieoczekiwanego zachowania po zniknięciu funkcji Lambda. Dobrą praktyką jest też posprzątanie tj. usunięcie np. nieużywanych więcej ról IAM.
"Ręczne" testowanie funkcji Lambda
Przed uruchomieniem skryptu testowego należy upewnić się, że w LocalStack istnieje testowe wiaderko (bucket) i jest w nim przykładowy plik png. Dla przypomnienia. W wersji Community zatrzymanie LocalStack wiąże się z usunięciem wszystkich zmian jakie zostały wcześniej wprowadzone więc, jeśli to nastąpiło koniecznym będzie ponowne utworzenie wiaderka i przesłanie pliku, który posłuży do testów.
awslocal s3 mb s3://testbucket
awslocal s3 cp test.png s3://testbucket
Skrypt testowy test_lambda_function.py
import boto3
import json
# Tworzenie klienta Lambda
lambda_client = boto3.client("lambda", endpoint_url="http://localhost:4566")
# Definiowanie testowego zdarzenia S3
test_event = {
"Records": [
{
"s3": {
"bucket": {
"name": "testbucket"
},
"object": {
"key": "test.png"
}
}
}
]
}
# Wywołanie funkcji Lambda
response = lambda_client.invoke(
FunctionName="my-resize-function",
InvocationType="RequestResponse",
Payload=json.dumps(test_event)
)
# Odczytanie odpowiedzi (jeśli InvocationType jest ustawione na 'RequestResponse')
if response.get("Payload"):
response_payload = json.loads(response["Payload"].read())
print(response_payload)
Powyższy test odpala funkcję lambda w sposób synchroniczny dzięki czemu możliwe jest wyświetlenie uzyskanej odpowiedzi. Ułatwia to testowanie. Zmiana InvocationType na Event spowodowałoby wywołanie asynchroniczne i w takim wypadku niemożliwym byłoby uzyskanie natychmiastowej odpowiedzi a funkcja json.loads zgłosiłaby błąd parsowania.
Po uruchomieniu testu (w wirtualnym środowisku)
python ./test_lambda_function.py
Created thumbnail thumb_test.png
Uzyskana odpowiedź potwierdza działanie funkcji co można dodatkowo potwierdzić sprawdzając zawartość wiaderka S3.
awslocal s3api list-objects --bucket testbucket
Konfiguracja Triggera S3
Ostatnim krokiem tego przykładowego wdrożenia jest stworzenie triggera w S3, tak aby uruchamiał funkcję Lambda za każdym razem, gdy nowy obraz zostanie przesłany do określonego wiadra.
awslocal s3api put-bucket-notification-configuration --bucket testbucket \
--notification-configuration '{
"LambdaFunctionConfigurations": [
{
"LambdaFunctionArn": "arn:aws:lambda:us-east-1:000000000000:function:my-resize-function",
"Events": ["s3:ObjectCreated:*"]
}
]
}'
Przesłanie nowego obrazka i sprawdzenie czy miniatura została automatycznie utworzona potwierdza jego działanie.
awslocal s3 cp test2.png s3://testbucket
awslocal s3api list-objects --bucket testbucket
{
"Contents": [
{
"Key": "test.png",
"LastModified": "2024-01-18T20:46:51+00:00",
"ETag": "\"4f4859a673e6b25e5f8811cfca26e174\"",
"Size": 50549,
"StorageClass": "STANDARD",
"Owner": {
"DisplayName": "webfile",
"ID": "75aa57f09aa0c8caeab4f8c24e99d10f8e7faeebf76c078efc7c6caea54ba06a"
}
},
{
"Key": "test2.png",
"LastModified": "2024-01-18T20:48:42+00:00",
"ETag": "\"4f4859a673e6b25e5f8811cfca26e174\"",
"Size": 50549,
"StorageClass": "STANDARD",
"Owner": {
"DisplayName": "webfile",
"ID": "75aa57f09aa0c8caeab4f8c24e99d10f8e7faeebf76c078efc7c6caea54ba06a"
}
},
{
"Key": "thumb_test.png",
"LastModified": "2024-01-18T20:47:38+00:00",
"ETag": "\"344c16804000106fe13bc91e28716e01\"",
"Size": 32042,
"StorageClass": "STANDARD",
"Owner": {
"DisplayName": "webfile",
"ID": "75aa57f09aa0c8caeab4f8c24e99d10f8e7faeebf76c078efc7c6caea54ba06a"
}
},
{
"Key": "thumb_test2.png",
"LastModified": "2024-01-18T20:48:42+00:00",
"ETag": "\"344c16804000106fe13bc91e28716e01\"",
"Size": 32042,
"StorageClass": "STANDARD",
"Owner": {
"DisplayName": "webfile",
"ID": "75aa57f09aa0c8caeab4f8c24e99d10f8e7faeebf76c078efc7c6caea54ba06a"
}
}
],
"RequestCharged": null
}
Instrukcja "Events": ["s3:ObjectCreated:*"] instruuje trigger aby uruchamiał funkcję lambda w przypadku utworzenia dowolnego obiektu (przesłania dowolnego pliku) w usłudze S3. Mimo, że w skrypcie lambda_function.py z handlerem funkcji lambda została zaimplementowana funkcja zgłaszająca wyjątek w przypadku przesłana do niej pliku innego niż png nie jest to optymalne rozwiązanie. W przypadku, gdy bucket S3 zawiera dużo plików innych niż png, unikanie ich przetwarzania przez funkcję Lambda może znacząco zmniejszyć liczbę wywołań funkcji Lambda, a co za tym idzie – obniżyć koszty. Trzeba pamiętać, że każde wywołanie funkcji Lambda jest płatne, a filtrując zdarzenia tak, aby uruchamiały funkcję Lambda tylko dla specyficznych typów plików, można ograniczyć liczbę niepotrzebnych wywołań i tym samym zmniejszyć koszty.
awslocal s3api put-bucket-notification-configuration --bucket testbucket \
--notification-configuration '{
"LambdaFunctionConfigurations": [
{
"LambdaFunctionArn": "arn:aws:lambda:us-east-1:000000000000:function:my-resize-function",
"Events": ["s3:ObjectCreated:*"],
"Filter": {
"Key": {
"FilterRules": [
{
"Name": "suffix",
"Value": ".png"
}
]
}
}
}
]
}'
Niestety, AWS S3 nie obsługuje bezpośrednio logiki wykluczającej, więc filtra eliminującego wywołanie funkcji Lambda dla plików z prefiksem thumb_ nie da się skonstruować dlatego w celu wyeliminowania zbędnych wywołań w tym przypadku trzeba poszukać innego rozwiązania. Dobrym podejściem jest zapisywanie miniaturek w odrębnym wiaderku co eliminuje dwa problemy.
- Zbędne wywołania
- Niebezpieczeństwo wywołań rekurencyjnych
Jak się okazuje nawet ograniczona edycja Community lokalnego środowiska AWS jest przydatna przy rozwijaniu rozwiązań opartych o usługi chmurowe Amazonu. Deweloperzy udoskonalający swoje implementacje nie muszą obawiać się limitów dotyczących wywołań, kłopotów związanych z błędami w kodzie jak np. te doprowadzające do nieograniczonej rekurencji. Mogą też przetestować wstępnie prototypy swoich programów bez wcześniejszego zagłębiania się w szczegóły polityki bezpieczeństwa. Naturalnie testowanie uprawnień też jest możliwe ale można to odłożyć na następną iterację spokojnie dopieszczając oprogramowanie krok po kroku.