Konwersja HTML na PDF w języku Python
Styczeń 12, 2025 | #python
000000
111000
000011
Pracując nad zadaniem polegającym na dodaniu do dokumentu publikowanego w formie HTML i PDF danych teleadresowych w postaci kodu QR, spotkałem się z problemem czytelności niewielkiego kodu. Ponieważ w grę wchodziło m.in. generowanie PDF-a - a miałem z tym kiedyś nie małe przeboje - zapowiadało się, że spędzę nad tym trochę czasu. Niekiedy przy takich okazjach robię na boku osobny skrypt, albo nawet niewielką aplikację aby poeksperymentować, albo zaimplementować coś na szybko - taki Proof of Concept (w skórcie PoC). W projekcie nie miałem możliwości zmiany narzędzia do generowania PDF-a (bez dobrych argumentów), ale ponieważ w trakcie urlopu też trzeba coś robić postanowiłem dodatkowo przetestować różne biblioteki Python-a oferujące możliwość konwersji HTML do PDF.
Generowanie QR kodu z danymi teleadresowymi w formacie vCard
QR kod w założeniu miał zawierać dane w formacie vCard (inaczej VCF (Virtual Contact File)). Są to wirtualne wizytówki, które przesłane e-mail-em, MMS-em czy zeskanowane z kodu QR można łatwo dodać do książki teleadresowej.
import vobject
def create_vcard(
name: str,
first_name: str | None = None,
last_name: str | None = None,
title: str | None = None,
phone: str | None = None,
email: str | None = None,
website: str | None = None,
address: str | None = None
) -> str:
v_card = vobject.vCard()
v_card.add('fn').value = name
if first_name or last_name:
n = v_card.add('n')
n.value = vobject.vcard.Name(
family=last_name,
given=first_name
)
if title:
v_card.add('title').value = title
if address:
adr = v_card.add('adr')
adr.type_param = 'WORK'
adr.value = vobject.vcard.Address(
street=address['street'],
city=address['city'],
code=address['postal_code'],
country=address['country']
)
if phone:
tel = v_card.add('tel')
tel.type_param = 'WORK,VOICE'
tel.value = phone
if email:
email_field = v_card.add('email')
email_field.type_param = 'INTERNET'
email_field.value = email
if website:
url = v_card.add('url')
url.type_param = 'WORK'
url.value = website
return v_card.serialize()
vcard_data = {
'name': 'Jan Kowalski',
'first_name': 'Jan',
'last_name': 'Kowalski',
'title': 'Software Developer',
'phone': '+48 123 456 789',
'email': 'jan.kowalski@example.com',
'website': 'https://example.com',
'address': {
'street': 'ul. Przykładowa 1',
'city': 'Miasto',
'postal_code': '00-000',
'country': 'Polska'
}
}
vcard = create_vcard(**vcard_data)
QR kod w formacie PNG
Początkowo wygenerowałem kod QR używając do tego biblioteki qrcode, która domyślnie generuje obrazki w formacie PNG.
import qrcode
# from qrcode.constants import ERROR_CORRECT_L
from io import BytesIO
import base64
def generate_qr_code_png(vcard: str) -> str:
qr = qrcode.QRCode(
# version=1,
# error_correction=ERROR_CORRECT_L,
# box_size=10,
# border=4
)
qr.add_data(vcard)
qr.make(fit=True)
buffer = BytesIO()
qr.make_image(fill='black', back_color='white').save(buffer, format='PNG')
img_base64 = base64.b64encode(buffer.getvalue()).decode('utf-8')
return f'data:image/png;base64,{img_base64}'
qr_uri_png = generate_qr_code_using_qrcode_png(vcard)
Przetestowałem też zaawansowane ustawienia zmieniając wartości zakomentowanych parametrów, ale na potrzeby tego eksperymentu pokazuję wyniki dla ustawień domyślnych.
QR kod w formacie SVG
Postanowiłem także wygenerować kod QR w formacie SVG, aby sprawdzić czy wpłynie to na czytelność kodu.
import qrcode.image.svg
def generate_qr_code_svg(vcard: str) -> str:
qr = qrcode.QRCode(
image_factory=qrcode.image.svg.SvgPathImage
)
qr.add_data(vcard)
qr.make(fit=True)
img = qr.make_image(attrib={'class': 'qr-code'})
return img.to_string(encoding='unicode')
qr_svg = generate_qr_code_using_qrcode_svg(vcard)
Obawiałem się o to, czy przy konwersji na PDF nie będzie problemu z formatem SVG. O narzędzia korzystające w tle z silników przeglądarek byłem spokojny. Natomiast biblioteki
weasyprint i xhtml2pdf stanowiły niewiadomą.
Przygotowanie kodu HTML do testów konwersji na PDF
Osadzenie QR kodu w strukturze HTML nie jest wyzwaniem w końcu mamy do czynienia ze standardowym plikiem PNG (lub jak w naszym przypadku plikiem zakodowanym do formatu base64) lub SVG. Odrobinę obaw miałem jednak w związku z kontrolą wielkości kodu QR a przede wszystkim ze skalowaniem go bez utraty jakości i czytelności. Nie ukrywam, że duże nadzieje pokładałem przede wszystkim w formacie SVG.
Renderowanie kodów QR to nie jedyne testy jakie zaplanowałem dla narzędzi konwersji kodu HTML do PDF. Z tego względu przygotowałem sobie trzy szablony html. Do wypełniania szablonów zmiennymi i renderowania html użyłem Jinja2.
from jinja2 import Environment, PackageLoader, select_autoescape
jinja = Environment(
loader=PackageLoader("app", "templates"),
autoescape=select_autoescape()
)
def generate_html(template, data):
return jinja.get_template(template).render(**data)
Kod HTML postanowiłem generować w locie, ale z uwagi na potrzebę porównania wersji HTML do wygenerowanego na ich podstawie pliku PDF przygotowałem także funkcję, która zapisuje wyrenderowany szablon do wynikowego pliku html.
def save_html(html_template, html_file):
with open(html_file, "w", encoding='utf-8') as file:
file.write(html_template)
Kod QR w formacie PNG i SVG oraz generowanie dynamiczne treści z użyciem JavaScript
Pierwszy szablon zawiera m.in. kod QR w dwóch formatach. W formie pliku PNG oraz w formacie SVG. Dane zostały minimalnie sformatowane, dlatego dadzą też okazję sprawdzić odzwierciedlenie styli CSS w pliku PDF. Dodatkowo adres email został zakodowany za pomocą JavaScriptu w celu obsofukacji. Testowanie skuteczności technik zaciemniania kodu nie jest przedmiotem tego eksperymentu ale pozwoli sprawdzić jak narzędzia do tworzenia PDF-ów z kodu HTML radzą sobie z treściami generowanymi dynamicznie - w tym wypadku przez JavaScript.
Plik ./app/templates/business_card_1.html
<html>
<head>
<meta charset='utf-8'>
<title>Business Card</title>
<link href='https://fonts.googleapis.com/css2?family=Roboto+Condensed&display=swap' rel='stylesheet'>
<style>
body {
font-family: 'Roboto Condensed', sans-serif;
}
.card {
border: 1px solid #000;
padding: 20px;
width: 300px;
text-align: center;
}
.card h2 {
font-size: 1.5em;
font-weight: bold;
}
.card p {
margin: 5px 0;
}
.card strong {
font-weight: bold;
}
.qr-container {
/* display: flex; */
justify-content: center;
align-items: center;
margin-top: 10px;
}
.qr-container .qr-code {
width: 150px;
height: 150px;
object-fit: contain;
}
</style>
</head>
<body>
<div class='card'>
<h2>{{ name}}</h2>
<p><strong>Phone:</strong> {{ phone }}</p>
<p><strong>Email:</strong> <a id="emailLinkID" href=""></a></p>
<p><strong>Website:</strong> <a href='{{ website }}'>{{ website }}</a></p>
<p><strong>Address:</strong> {{ address.street }}<br>{{ address.city }}, {{ address.postal_code }}, {{ address.country }}</p>
<div class='qr-container'>
<img src='{{ qr_uri_png }}' class="qr-code" alt='QR Code' />
{{ qr_svg|safe }}
</div>
</div>
<script>
const emailForm = document.getElementById("emailLinkID");
emailForm?.setAttribute("href", "mailto:".concat(window.atob(window.btoa("{{ email }}"))));
emailForm.textContent = window.atob(window.btoa("{{ email }}"));
</script>
</body>
</html>
Zakomentowana linia kodu w CSS /* display: flex; */ została zachowana w przykładzie nie bez powodu. Odniosę się do niej przy okazji testowania weasyprint.
Wyrenderowany HTML z tego szablonu wygląda następująco:

Uwaga to co widzisz to SVG ale możesz podejrzeć jak wygląda rzeczywisty HTML business_card_1.html
Rozbudowany CSS
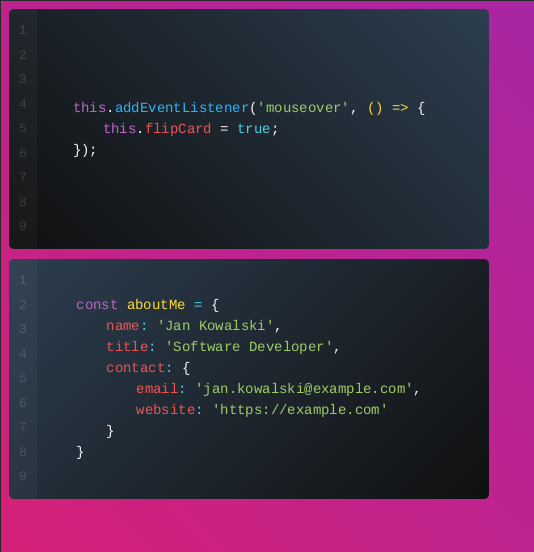
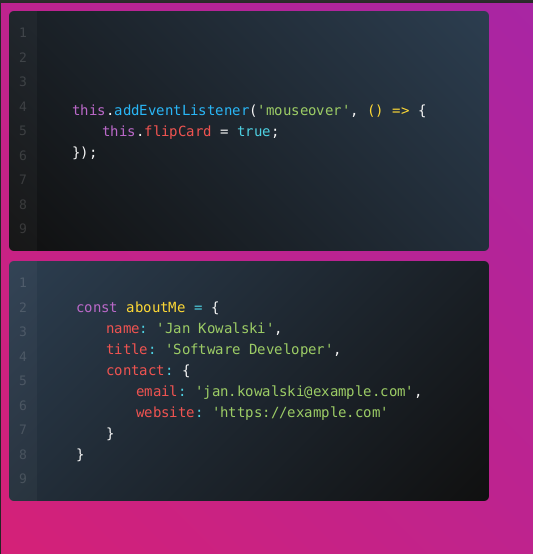
Drugi szablon ma na celu sprawdzenie jak konwertery PDF poradzą sobie z nieco bardziej rozbudowanym CSS-em. W tym wypadku skorzystałem z gotowego projektu wizytówki przygotowanego przez - Joshua Ward.
Plik ./app/templates/business_card_2.html
<html>
<head>
<meta charset='utf-8'>
<title>Business Card</title>
<style>
*, *:before, *:after {
box-sizing: border-box;
outline: none;
}
html {
font-family: "Source Sans Pro", sans-serif;
font-size: 16px;
font-smooth: auto;
font-weight: 300;
line-height: 1.5;
color: #444;
}
body {
position: relative;
display: flex;
align-items: center;
justify-content: center;
width: 100%;
height: 100vh;
background: linear-gradient(45deg, #E91E63, #9C27B0);
}
code, .card .line-numbers {
font-family: "Lucida Console", Monaco, monospace;
font-size: 14px;
}
.card {
position: relative;
width: 30rem;
height: 15rem;
perspective: 150rem;
}
.card-front, .card-back {
position: absolute;
width: 100%;
height: 100%;
display: flex;
align-items: center;
justify-content: center;
margin: auto;
border-radius: 5px;
box-shadow: 0 1.5rem 4rem rgba(0, 0, 0, 0.4);
transition: 0.9s cubic-bezier(0.25, 0.8, 0.25, 1);
backface-visibility: hidden;
overflow: hidden;
}
.card-front:before, .card-front:after, .card-back:before, .card-back:after {
position: absolute;
}
.card-front:before, .card-back:before {
top: -40px;
right: -40px;
content: "";
width: 80px;
height: 80px;
background-color: rgba(255, 255, 255, 0.08);
transform: rotate(45deg);
z-index: 1;
}
.card-front:after, .card-back:after {
content: "+";
top: 0;
right: 10px;
font-size: 24px;
transform: rotate(45deg);
z-index: 2;
}
.card-front {
width: 100%;
height: 100%;
background: linear-gradient(45deg, #101010, #2c3e50);
}
.card-front:after {
color: #212f3c;
}
.card-back {
background: linear-gradient(-45deg, #101010, #2c3e50);
transform: rotateX(180deg);
}
.card-back:after {
color: #11181f;
}
.card:hover .card-front {
transform: rotateX(-180deg);
}
.card:hover .card-back {
transform: rotateX(0deg);
}
.card .line-numbers {
position: absolute;
top: 0;
left: 0;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
height: 100%;
margin: 0;
padding: 0 10px;
background-color: rgba(255, 255, 255, 0.03);
font-size: 13px;
}
.card .line-numbers > div {
padding: 2.5px 0;
opacity: 0.15;
}
.card code, .card .line-numbers {
color: whitesmoke;
}
.card .indent {
padding-left: 30px;
}
.card .operator {
color: #4dd0e1;
}
.card .string {
color: #9ccc65;
}
.card .variable {
color: #BA68C8;
}
.card .property {
color: #ef5350;
}
.card .method {
color: #29b6f6;
}
.card .function {
color: #FDD835;
}
.card .boolean {
color: #4dd0e1;
}
</style>
</head>
<body>
<div class="card">
<div class="card-back">
<div class="line-numbers">
<div>1</div><div>2</div><div>3</div><div>4</div><div>5</div><div>6</div><div>7</div><div>8</div><div>9</div>
</div>
<code>
<div>
<span class="variable">const </span><span class="function">aboutMe</span><span class="operator"> = </span>{
</div>
<div class="indent">
<span class="property">name</span><span class="operator">: </span><span class="string">'{{ name }}'</span>,
</div>
<div class="indent">
<span class="property">title</span><span class="operator">: </span><span class="string">'{{ title }}'</span>,
</div>
<div class="indent">
<span class="property">contact</span><span class="operator">:</span> {
<div class="indent">
<span class="property">email</span><span class="operator">: </span><span class="string">'{{ email }}'</span>,
</div>
<div class="indent">
<span class="property">website</span><span class="operator">: </span><span class="string">'{{ website }}'</span>
</div>
<div>}</div>
</div>
<div>}</div>
</code>
</div>
<div class="card-front">
<div class="line-numbers">
<div>1</div><div>2</div><div>3</div><div>4</div><div>5</div><div>6</div><div>7</div><div>8</div><div>9</div>
</div>
<code>
<div>
<span class="variable">this</span>.<span class="method">addEventListener</span>(<span class="string">'mouseover'</span>,
<span class="function">() =></span> {
</div>
<div class="indent">
<span class="variable">this</span>.<span class="property">flipCard</span> = <span class="boolean">true</span>;
</div>
<div>});</div>
</code>
</div>
</div>
</body>
Po wyrenderowaniu wizytówka prezentuje się tak:

Możesz podejrzeć jak wygląda rzeczywisty HTML business_card_2.html
W podglądzie wydruku wizytówka standardowo pozbawiona jest kolorów tła:
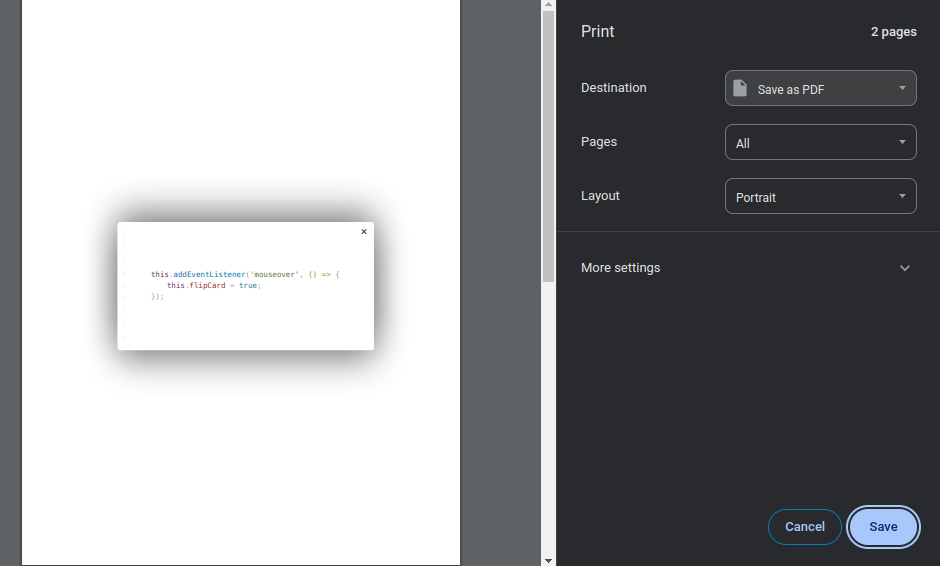
@media print
Dokument w formacie PDF ze swej natury ma raczej statyczny charakter i nikt nie oczekuje aby reagował na zdarzenia JavaScript jak hover, click (nie licząc odsyłaczy do innych zasobów) it.. Z tego powodu często chcielibyśmy aby efekt końcowy przypominał bardziej wydruk niż print-screen. Można oczekiwać, że zwłaszcza biblioteki korzystające w tle z silników przeglądarek będą w trakcie konwersji strony www do PDF respektować reguły CSS przeznaczona dla widoku wydruku. Dlatego ostatni z szablonów jest dokładnie taki sam jak poprzedni a dodano do niego jedynie reguły CSS @media print.
Plik ./app/templates/business_card_3.html
@media print {
body {
position: static;
display:block;
width: auto;
height: auto;
/* background: none; */
}
.card-front:before, .card-front:after, .card-back:before, .card-back:after {
display: none;
}
.card-front, .card-back {
box-shadow: none;
transition: none;
}
.card:hover .card-front, .card:hover .card-back {
transform: rotateX(0deg);
}
.card-back {
transform: rotateX(0deg);
top: 250px;
}
.card {
print-color-adjust: exact;
-webkit-print-color-adjust: exact;
}
}
Dzięki dodatkowym stylom wyżej zaprezentowana wizytówka w podglądzie wydruku prezentuje się następująco:
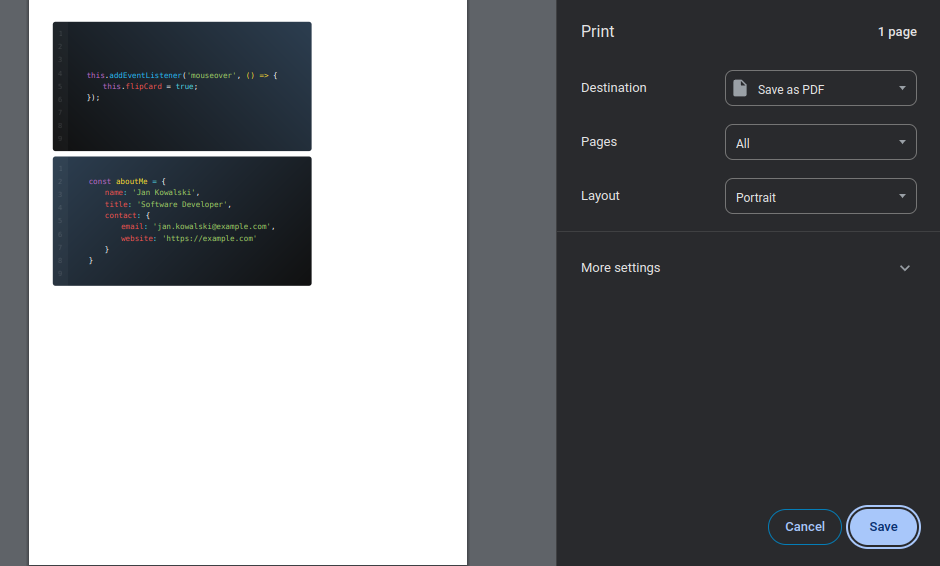
Możesz podejrzeć jak wygląda rzeczywisty HTML business_card_3.html
Konwersja HTML na PDF w języku Python
Zależy nam aby wygenerowany PDF możliwie dobrze odzwierciedlał wygląd wyrenderowanego kodu HTML.
W przypadku pierwszego szablonu skupimy uwagę na:
- strukturze dokumentu
- pogrubieniu wyróżnionych słów
- poprawnym wyświetleniu obu kodów QR zarówno w wersji PNG jak i SVG
- wyświetleniu treści adresu email, który - jak przypominam - zbudowany jest dynamicznie z użyciem JavaScript
W drugim przypadku testowym interesuje nas:
- struktura dokumentu w tym jej pozycjonowanie w centrum strony
- odwzorowanie kaskadowych styli CSS i wygląd wizytówki tak jak widzi ją użytkownik, który nie podejmuje żadnych akcji (nie najeżdża myszką na interaktywny obiekt)
Ostatni wariant pozwoli sprawdzić:
- czy respektowane są style dla trybu wydruku
XHTML2PDF
Biblioteka xhtml2pdf (dawniej PISA) jest napisana w czystym Pythonie. Parsuje kod HTML i CSS za pomocą parsera html5lib (bądź w starszych wersjach inne parsery) przekształcając go do wewnętrznej reprezentacji, która jest zrozumiała dla ReportLab - silnika (toolkit) odpowiedzialnego za faktyczne tworzenie pliku PDF.
Generowanie PDF z kodu HTML przy użyciu xhtml2pdf
from xhtml2pdf import pisa
def generate_pdf_using_xhtml2pdf(html, pdf_path):
try:
with open(pdf_path, "wb") as pdf_file:
pisa_status = pisa.CreatePDF(html, dest=pdf_file)
print(f"Business card has been saved as {pdf_path}")
return not pisa_status.err
except Exception as e:
print(f"Failed to export to PDF using xhtml2pdf: {e}")
return False
from pathlib import Path
base_path = Path.cwd()
output_path = base_path / "output"
for i in range(1, 4):
html = generate_html(f"business_card_{i}.html", vcard_data)
generate_pdf_using_xhtml2pdf(html=html, pdf_path=output_path / f"xhtml2pdf_{i}.pdf")
Wizytówka 1. w formacie PDF wygenerowana przez xhtml2pdf
Wynik pierwszego zadania nie napawa optymizmem. Widać, że narzędzie poza tym, że wyświetliło treść nie poradziło sobie ze stylami CSS, treścią renderowaną przez JavaScript a także z QR kodem w formacie SVG.
| xhtml2pdf | HTML | |
|---|---|---|
 |
vs. | |
WIzytówka 2 i 3 w formacie PDF wygenerowana przez xhtml2pdf
Wynik zadania 2 i 3 był w tym wypadku identyczny i nie ma co tu porównywać do wzorca. Potwierdza to, że xhtml2pdf nie nadaje się do odwzorowywanie HTML-a sformatowanego przy pomocy nieco bardziej złożonego CSS-a. Choć projekt xhtml2pdf jest cały czas rozwijany (w czasie pisania tego artykułu ostatnie wydanie miało miejsce 8 czerwca 2024 r.), nie sądzę aby były to prace inne, niż tylko utrzymaniowe typu aktualizacja zależności do najnowszych wersji, ewentualnie poprawa drobnych błędów.

WeasyPrint
Biblioteka weasyprint także jest napisana w języku Python. Dzięki lxml tworzy ona wewnętrzną reprezentację dokumentu (tree), oblicza style i strukturę layoutu przy pomocy tinycss2. Następnie wykorzystuje Pango do składu tekstu oraz Cairo do renderowania grafiki i zapisania go w formacie PDF (lub innego typu, np. PNG).
Generowanie PDF z kodu HTML przy użyciu WeasyPrint
from weasyprint import HTML
def generate_pdf_using_weasyprint(html, pdf_file):
try:
HTML(string=html).write_pdf(pdf_file)
print(f"Business card has been saved as {pdf_file}")
except Exception as e:
print(f"Failed to export to PDF using WeasyPrint: {e}")
from pathlib import Path
base_path = Path.cwd()
output_path = base_path / "output"
for i in range(1, 4):
html = generate_html(f"business_card_{i}.html", vcard_data)
generate_pdf_using_weasyprint(html=html, pdf_file=output_path / f"weasyprint_{i}.pdf")
Wizytówka 1 w formacie PDF wygenerowana przez WeasyPrint
Wynik pierwszego zadania pokazuje, że weasyprint poradził sobie ze strukturą dokumentu, i że w jego przypadku nie ma predefiniowanych styli dla niektórych elementów HTML tak jak ma to miejsce w przeglądarkach. W tym wypadku teksty otoczone tagiem <strong> nie został pogrubione. Pracując z tą biblioteką warto stosować arkusze styli resetujące domyślne style przeglądarki i definiujące wygląd każdego spodziewanego elementu HTML w dokumencie.
Adres email renderowany przy pomocy JavaScript niestety nie pokazał się na PDF-ie więc biblioteka weasyprint nie oferuje wsparcia w tym zakresie.
Nie zauważyłem za to żadnego problemu z kodem QR. Zarówno w formacie PNG, jak i SVG kody na pierwszy rzut oka wyglądały identycznie i (choć poniższa grafika z uwagi na obniżoną jakość nie pozwala tego udowodnić) oba kody były czytelne.
| weasyprint | HTML | |
|---|---|---|
 |
vs. | |
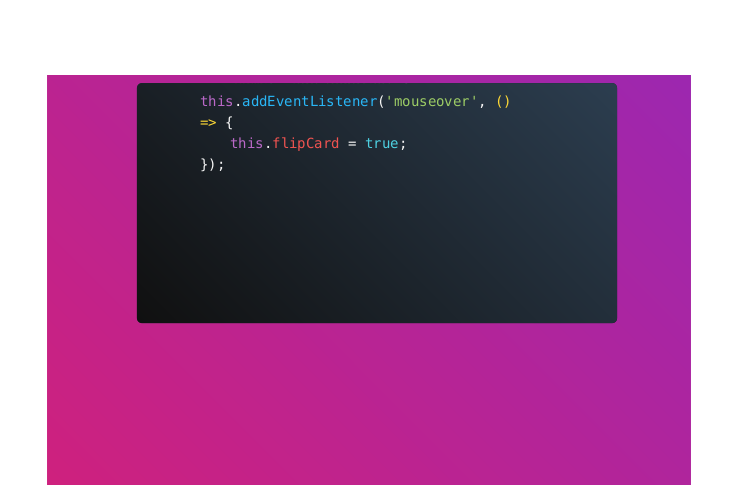
Wizytówka 2 w formacie PDF wygenerowana przez WeasyPrint
WeasyPrint domyślnie wyświetla tło więc w przypadku tej biblioteki nie trzeba się o to martwić. Powstałe marginesy to zapewne kwestia ustawień, ale style odpowiedzialne za wyrównanie tekstu w pionie są wyzwaniem dla tinycss2.
| weasyprint | HTML | |
|---|---|---|
 |
vs. |  |
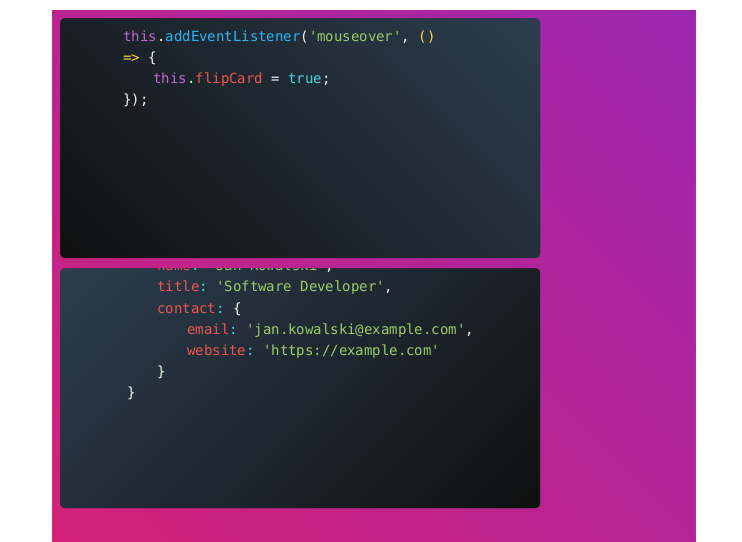
Wizytówka 3 w formacie PDF wygenerowana przez WeasyPrint
Choć weasyprint respektuje style dla wydruku to problem z pozycjonowaniem nie daje zadowalającego rezultatu.
Python-PDFKit (wkhtmltopdf)
Python pdfkit to wrapper (opakowanie) napisane w Python (istnieją też wersje dla innych języków m.in. Ruby, JavaScript) na wkhtmltopdf - program renderujący kod HTML za pośrednictwem silnika WebKit i zapisującego go ostatecznie w formacie PDF.
Generowanie PDF z kodu HTML przy użyciu pdfkit i wkhtmltopdf
import pdfkit
def generate_pdf_using_wkhtmltopdf(html, pdf_file):
try:
options = {
'print-media-type': None,
'background': None,
}
pdfkit.from_string(html, pdf_file, options=options)
print(f"Business card has been saved as {pdf_file}")
except Exception as e:
print(f"Failed to export to PDF using wkhtmltopdf: {e}")
from pathlib import Path
base_path = Path.cwd()
output_path = base_path / "output"
for i in range(1, 4):
html = generate_html(f"business_card_{i}.html", vcard_data)
generate_pdf_using_wkhtmltopdf(html=html, pdf_file=output_path / f"wkhtmltopdf_{i}.pdf")
Wkhtmltopdf to program działający w linii komend, który można wywołać z licznymi opcjami.
wkhtmltopdf --print-media-type input.html output.pdf
Zwróć uwagę, że w przypadku niektórych opcji (tych, które w wkhtmltopdf nie oczekują wartości, tylko samej flagi, np. --print-media-type lub --no-print-media-type) w słowniku opcji pdfkit przypisujemy wartość None.
Wspomnę tylko, że testując użycie obu tych opcji nie zauważyłem różnicy i w obu przypadkach silnik WebKit interpretował style przeznaczone do druku @media print tak jakby pdfkit wymuszał opcję print-media-type. Za to używając opcji no-background można było usunąć grafikę czy kolor tła.
Wizytówka 1 w formacie PDF wygenerowana przez pdfkit
Wynik jest nieomal identyczny do weasyprint. Także wkhtmltopdf nie pogrubił zawartości tagów <strong> i nie wyrenderował dynamicznej treści, choć prosty JavaScript powinien być teoretycznie osiągalny dla silnika WebKit. Kody QR zostały za to wyświetlone poprawnie w obu formatach.
| pdfkit (wkhtmltopdf) | HTML | |
|---|---|---|
 |
vs. | |
Próbowałem dodać opcje aktywujące JavaScript.
options = {
...
'enable-javascript': None,
'javascript-delay': 2000,
}
pdfkit.from_string(html, pdf_file, options=options)
Niestety nie spowodowało to, że w wyniku zobaczyłem na dokumencie PDF adres email. Zwiększanie javascript-delay (domyślnie jest 200) nic nie zmieniało.
Wizytówka 2 w formacie PDF wygenerowana przez pdfkit
Prawdopodobnie wkhtmltopdf używa starszej wersji silnika WebKit, który ma problemy z niektórymi dyrektywami CSS-a. W każdym razie nie poradził sobie z centrowaniem wizytówki.
| pdfkit (wkhtmltopdf) | HTML | |
|---|---|---|
 |
vs. | |
Wizytówka 3 w formacie PDF wygenerowana przez pdfkit
Wynik trzeciej próby potwierdza, że wkhtmltopdf uwzględnia style dedykowane drukarkom, ale że też generalnie radzi sobie z CSS-em całkiem nieźle i choć może nie jest idealnie to do większości zadań się sprawdzi.
Pyppeteer
Pyppeteer to biblioteka Pythona, będąca nieoficjalnym portem popularnego narzędzia Puppeteer (napisanego w Node.js i rozwijanego przez zespół odpowiedzialny za Chrome DevTools w firmie Google). Puppeteer pozwala na automatyzację czynności w przeglądarce Chrome (lub Chromium) w trybie bezgłowym (ang. headless) - czyli bez interfejsu graficznego. Przydaje się do testów frontendu aplikacji webowych, scrapingu stron, monitorowania i raportowania stanu lub zmian na stronach www itp. W naszym przypadku sprawdza się także jako narzędzie konwersji kodu HTML do PDF.
Generowanie PDF z kodu HTML przy użyciu pyppeteer
from pyppeteer import launch
async def generate_pdf_using_pyppeteer(html, pdf_file):
browser = await launch(
headless=True,
args=['--no-sandbox']
)
options = {
"printBackground": True
}
try:
page = await browser.newPage()
await page.setContent(html)
await page.pdf({'path': pdf_file, **options})
print(f"Business card has been saved as {pdf_file}")
except Exception as e:
print(f"Failed to export to PDF using Pyppeteer: {e}")
finally:
await browser.close()
import asyncio
from pathlib import Path
base_path = Path.cwd()
output_path = base_path / "output"
tasks = []
for i in range(1, 4):
html = generate_html(f"business_card_{i}.html", vcard_data)
tasks.append(generate_pdf_using_pyppeteer(html=html, pdf_file=output_path / f"pyppeteer_{i}.pdf"))
async def generate_pdf_using_async_functions():
if tasks:
results = await asyncio.gather(*tasks, return_exceptions=False)
for result in results:
if isinstance(result, Exception):
print(result)
Wizytówka 1 w formacie PDF wygenerowana przez pyppeteer
Spodziewałem się, że pyppeteer poradzi sobie z każdym zadaniem z tego eksperymentu. I rzeczywiście o ile kaskadowe style CSS i kod QR w formacie PNG i SVG zostały odwzorowane wzorcowo, o tyle zaskoczył mnie brak adresu email, który jest generowany za pomocą prostej funkcji JavaScript.
| pyppeteer | HTML | |
|---|---|---|
 |
vs. | |
W puppeteer napisanym w Node.js do metody setContent obiektu Page można przekazać dodatkowe opcje w tym waitUntil pozwalającej wpłynąć na zachowanie przeglądarki, która poczeka na wyrenderowanie strony w zależności od wybranej opcji.
await page.setContent(reuslt, {waitUntil: "domcontentloaded"});
W wersji pyppeteer metoda setContent nie przyjmuje opcji, dlatego trzeba sobie inaczej poradzić. Najprostszym rozwiązaniem jest "poczekać" na wykonanie JS w HTML.
await page.setContent(html)
await asyncio.sleep(0.5)
await page.pdf({'path': pdf_file, **options})
Zaproponowany sposób jest nieelegancki, ale działa. Gdybym jednak miał zdecydować się na produkcyjne użycie pyppeteer-a poszukałbym zgrabniejszego rozwiązania.
Wizytówka 2 w formacie PDF wygenerowana przez pyppeteer
Ustawienie opcji printBackground na True sprawiło, że widok HTML i wygenerowany na jego podstawie PDF wyglądają bliźniaczo podobnie. Myślę, że wynik jest w pełni zadowalający i choć jestem w stanie dostrzec drobne różnice to są one pomijalne.
| pyppeteer | HTML | |
|---|---|---|
 |
vs. | |
Wizytówka 3 w formacie PDF wygenerowana przez pyppeteer
Style dla wydruku są respektowane przez pyppeteer-a, a gdyby usunąć wspomnianą już opcję printBackground to widzielibyśmy czarne wizytówki na białym tle.
Playwright
Nad rozwojem playwright pieczę sprawuje Microsoft mimo to, są to otwartoźródłowe (ang. open-source) biblioteki umożliwiające automatyzację przeglądarek internetowych (m.in. Chrome, Firefox, Edge, WebKit) w wielu językach programowania - w tym w Pythonie. Udostępniają zestaw narzędzi i funkcji przydatnych podczas realizacji testów end-to-end (E2E), web scrapingu / crawlingu, testów wizualnych i wydajnościowych oraz generowania PDF-ów.
Generowanie PDF z kodu HTML przy użyciu playwright
from playwright.async_api import async_playwright
async def generate_pdf_using_playwright(html, pdf_file, browser_name="chromium", channel_name='chromium'):
options = {
"print_background": True
}
try:
async with async_playwright() as p:
browser = await getattr(p, browser_name).launch(channel=channel_name)
page = await browser.new_page()
await page.set_content(html)
await page.pdf(path=pdf_file, **options)
await browser.close()
print(f"Business card has been saved as {pdf_file}")
except Exception as e:
print(f"Failed to export to PDF using playwright: {e}")
Ponieważ playwright w tle może używać różnych silników przeglądarek postanowiłem wypróbować wszystkie :)
import asyncio
from pathlib import Path
base_path = Path.cwd()
output_path = base_path / "output"
tasks = []
playwright_channels = {
"chromium": ["chromium", "chrome", "msedge"],
"firefox": ["firefox"],
"webkit": ["webkit"],
}
for i in range(1, 4):
html = generate_html(f"business_card_{i}.html", vcard_data)
for browser, channels in playwright_channels.items():
for channel in channels:
tasks.append(generate_pdf_using_playwright(
html=html,
pdf_file=output_path / f"playwright_{browser}_{channel}_{i}.pdf",
browser_name=browser,
channel_name=channel
))
async def generate_pdf_using_async_functions():
if tasks:
results = await asyncio.gather(*tasks, return_exceptions=False)
for result in results:
if isinstance(result, Exception):
print(result)
Dla prób użycia Firefox i Webkit do generowania PDF otrzymałem błąd:
Failed to export to PDF using playwright: Page.pdf: PDF generation is only supported for Headless Chromium
Po sprawdzeniu w dokumentacji tylko Chromium w playwright ma oficjalne wsparcie dla page.pdf()
Wizytówka 1 w formacie PDF wygenerowana przez playwright
Niezależnie czy użyłem Chromium w wersji chrome, chromium czy msedge wyniki otrzymałem identyczne (a przynajmniej ja ich nie dostrzegłem) dlatego prezentuję tylko jeden wynik.
I jest dobrze. Wszystkie wymagania zostały spełnione. Dokument układa się w prawidłową strukturę. Etykiety są pogrubione i nawet wygenerowany przez JavaScript email widoczny jest na PDF-ie bez konieczności stosowania niestandardowych opcji.
| playwright | HTML | |
|---|---|---|
 |
vs. | |
Uwaga! - Wygenerowana wizytówka wydaje się być nieco węższa ale należy pamiętać, że w obu egzemplifikacjach mamy do czynienia z obrazkami - zrzutem ekranu PDF do PNG i przekonwertowanym kodem HTML do SVG więc w rzeczywistości może to wyglądać nieco inaczej.
Wizytówka 2 w formacie PDF wygenerowana przez playwright
Widać drobne różnice w kolorach i cieniach, ale podobnie jak to miało miejsce w przypadku pyppeteer postawiłem na minimalną konfigurację ograniczającą się jedynie do ustawienia opcji "print_background": True. Zważywszy, że do wygenerowania PDF-a playwright także używa Chromium można było spodziewać się podobnych wyników i tak też jest.
| playwright | HTML | |
|---|---|---|
 |
vs. | |
Wizytówka 3 w formacie PDF wygenerowana przez playwright
Playwright także respektuje style dla wydruku.
Podsumowanie
Biblioteki oferujące konwersję HTML na PDF w Python-ie możemy z grubsza podzielić na te wykorzystujące w tle silniki przeglądarek internetowych i takie, które tego nie robią. Na podstawie przeprowadzonych eksperymentów mogę stwierdzić, że te pierwsze z wymienionych lepiej sobie radzą, ale to nie znaczy że weasyprint czy xhtml2pdf nie mają niczego do zaoferowania zwłaszcza jeśli potrzebne są rozwiązania lekkie (z mniejszą ilością zależności) i szybkie.
Narzut jaki stanowi uruchomienie przeglądarki z pewnością musi odbić się na wydajności. W zamian dostajemy większą zgodność z CSS-ami, wsparcie dla JavaScript i dodatkowe funkcjonalności oferowane przez silniki przeglądarek - zwłaszcza oferowane przez pyppeteer i playwright, których funkcja druku do formatu PDF jest tylko jedną z wielu możliwości i wcale nie najważniejszą, gdyż oba projekty są o wiele częściej wykorzystywane do zadań związanych z automatyzacją i testowaniem. Obie biblioteki oferują też interfejs asynchroniczny co nie jest bez znaczenia jeśli w grę wchodzą jakieś mocno rozbudowane operacje.
Na zakończenie dodam jeszcze, że przedstawione tu skrypty uruchamiałem w kontenerze Dockera do stworzenia, którego użyłem następujących plików.
Dockerfile
FROM python:3.12-slim
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
ENV PYTHONPATH "${PYTHONPATH}:/"
ENV HOME=/app
ARG USERNAME=default
ARG GROUPNAME=$USERNAME
ARG USER_UID=1000
ARG USER_GID=$USER_UID
RUN groupadd -g ${USER_GID} ${GROUPNAME} \
&& useradd -m -d ${HOME} -s /bin/bash -g ${GROUPNAME} -u ${USER_UID} ${USERNAME} \
&& mkdir -p /etc/sudoers.d \
&& echo "${USERNAME} ALL=(ALL) NOPASSWD: ALL" > /etc/sudoers.d/${USERNAME} \
&& chmod 0440 /etc/sudoers.d/${USERNAME}
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
build-essential \
cargo \
curl \
gpg \
libnss3 \
libatk-bridge2.0-0 \
libcups2 \
libxcomposite1 \
libxdamage1 \
libxrandr2 \
libgbm1 \
libpango1.0-0 \
libcairo2 \
libasound2 \
libxshmfence1 \
libffi-dev \
libjpeg-dev \
libxml2-dev \
libxslt-dev \
pkg-config \
wkhtmltopdf \
zlib1g-dev \
--no-install-recommends \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/* \
&& curl https://sh.rustup.rs -sSf | sh -s -- -y \
&& export PATH="$HOME/.cargo/bin:$PATH" \
&& python3 -m pip install --upgrade pip
ENV PATH="/root/.cargo/bin:${PATH}"
ENV PLAYWRIGHT_BROWSERS_PATH=/ms-playwright
COPY ./requirements.txt /requirements.txt
RUN pip3 install --no-cache-dir -r /requirements.txt \
&& mkdir -p /ms-playwright \
&& chmod -R 777 /ms-playwright \
&& playwright install --with-deps chromium chrome msedge firefox webkit
WORKDIR ${HOME}
COPY ./app ${HOME}
USER ${USERNAME}
CMD ["/bin/sh"]
requirements.txt
asyncio==3.4.3
html5lib==1.1
Jinja2==3.1.5
pdfkit==1.0.0
playwright==1.46.0
pyppeteer==2.0.0
qrcode==8.0
segno==1.6.1
vobject==0.9.9
weasyprint==53.0
xhtml2pdf==0.2.16
docker-compose.yml
services:
app:
build:
context: .
dockerfile: Dockerfile
args:
USER_UID: ${USER_UID:-1000}
USER_GID: ${USER_GID:-1000}
volumes:
- ./app:/app
restart: no