Asynchroniczne FastAPI w Dockerze
Kwiecień 25, 2024 | #python , #async , #fastapi
000010
100101
011010
Przystępując do realizacji mikroserwisu od samego początku trzeba się liczyć z tym, że będzie on funkcjonował w ramach większej infrastruktury najprawdopodobniej opartej o technologie chmurowe. Kubernetes wydaje się wyrastać na lidera a kontenery zdają się być naturalnym środowiskiem dla aplikacji - w szczególności dla rozbudowanych wielokomponentowych struktur. Między innymi z tego powodu w cyklu życia aplikacji Docker zatrudniany jest już na etapie dewelopmentu. Użycie Dockera przyzwyczaja dewelopera do pracy z aplikacją w wyizolowanym środowisku i zbliża do konfiguracji produkcyjnej.
Wybór frameworka FastAPI do budowy mikroserwisu nie jest przypadkowy. Framework ten wyróżnia się na tle innych rozwiązań szybkością działania, łatwością użycia i bogactwem funkcji. Dzięki wykorzystaniu asynchroniczności i oparciu na standardzie Python type hints, FastAPI pozwala na budowę wydajnych i czytelnych API. Funkcje asynchroniczne są kluczowe w kontekście mikroserwisów, gdzie aplikacja musi obsługiwać wiele równoległych żądań bez blokowania się nawzajem. Pozwala to na efektywne wykorzystanie zasobów i zapewnienie wysokiej skalowalności.
Artykuł przedstawia:
- jak skonfigurować projekt bazujący na frameworku FastAPI i bazie danych Postgresql w kontenerze Docker-a,
- jak łączyć się z bazą przy użyciu SQLAlchemy w sposób asynchroniczny i zainicjować migracje Alembic
- jak definiować asynchroniczne endpointy FastAPI?
Konfiguraca kontenerów PostgreSQL i Python dla aplikacji FastAPI
Docelowa struktura projektu jest bardziej rozbudowana ale w tym punkcie będą omawiane następujące pliki i katalogi.
project/
├── app/
│ ├── api/
│ │ ├── v1/
│ │ │ ├── __init__.py
│ │ │ └── ping.py
│ │ └── __init__.py
│ ├── core/
│ │ ├── __init__.py
│ │ └── config.py
│ ├── __init__.py
│ └── main.py
├── docker/
│ └── fastapi/
│ └── Dockerfile
├── .env
├── .env.template
├── docker-compose.yml
└── requirements.txt
Dockerfile rozszerzajacy obraz Python-a, na potrzeby aplikacji FastAPI
Osadzenie projektu FastAPI w Dockerze jest stosunkowo proste.
FROM python:3.12.1-alpine3.19
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
ENV PYTHONPATH "${PYTHONPATH}:/"
ENV HOME=/app
ARG USERNAME=default
ARG GROUPNAME=$USERNAME
ARG USER_UID=1000
ARG USER_GID=$USER_UID
RUN addgroup -g ${USER_GID} ${GROUPNAME} \
&& adduser -D ${USERNAME} -G ${GROUPNAME} -u ${USER_UID} -h ${HOME} \
&& mkdir -p /etc/sudoers.d \
&& echo "${USERNAME} ALL=(ALL) NOPASSWD: ALL" > /etc/sudoers.d/${USERNAME} \
&& chmod 0440 /etc/sudoers.d/${USERNAME}
RUN apk update \
&& apk add --no-cache \
build-base \
musl-dev \
postgresql-dev \
python3-dev \
&& pip install --upgrade pip
WORKDIR ${HOME}
COPY ./requirements.txt ${HOME}/requirements.txt
RUN pip install -r requirements.txt
COPY ./app ${HOME}
USER ${USERNAME}
Plik ./docker/fastapi/Dokerfile przedstawiony powyżej bazuje na obrazie Pythona w wersji 3.12 działającym na lekkim systemie operacyjnym Alpine Linux, którego największą zaletą jest mała wielkość i bezpieczeństwo.
O różnych obrazach Dockera i trzymaniu kontenerów w ryzach przeczytasz w artykule Wykorzystanie miejsca na dysku w pracy z Docker.
Następnie ustawiane są zmienne środowiskowe:
PYTHONDONTWRITEBYTECODE=1instruuje Pythona, aby nie zapisywał plików.pyc(skompilowanych plików bytecode), co sprzyja utrzymaniu niewielkich rozmiarów kontenerów,PYTHONUNBUFFERED=1powoduje, że wyjście stdout i stderr jest wyświetlane w czasie rzeczywistym bez buforowania. Jest to ważne w środowisku kontenerowym z punktu widzenia monitorowania stanu aplikacji,ENV PYTHONPATH "${PYTHONPATH}:/"- dodaje katalog główny (/) doPYTHONPATH, co w przypadku tej aplikacji umożliwi importowanie modułów z katalogu./appz użyciem przedrostkaapp.co jest o tyle ważne, że przedrostek ten będzie stanowił rodzaj namespace dla modułów aplikacji
Kolejne linie pozwalają ustawić w Dockerze użytkownika identycznego jak na hoście (z takim samym identyfikatorem użytkownika UID i grupy GID). Dzięki temu narzędzia działające wewnątrz kontenera a zmieniające pliki w podmontowanych katalogach - takie jak ruff, black, alembic itp. będą miały prawa zapisu i żaden nowo utworzony plik - patrz migracja nie zostanie utworzony z uprawnieniami root-a.
Instrukcja RUN apk update ... pip install --upgrade pip aktualizuje indeks pakietów systemu Alpine i instaluje niezbędne pakiety oraz narzędzia deweloperskie potrzebne do kompilacji zależności Pythona.
Zależności Python niezbędne do realizacji asynchronicznej aplikacji FastAPI
Wspomniane zależności wymienione są w pliku ./requirements.txt
alembic==1.13.1
asyncpg==0.29.0
fastapi==0.110.1
pydantic==2.6.4
pydantic-settings==2.2.1
python-dotenv==1.0.1
python-multipart==0.0.9
sqlalchemy[asyncio]==2.0.29
uvicorn==0.29.0
# DEV
httpx==0.27.0
pytest==8.1.1
pytest-asyncio==0.23.6
ruff==0.3.5
Docker compose narzędziem koordynacji kontenerów Postgres i FastAPI
Plik ./docker-compose.yml przedstawia konfigurację dwóch serwisów postgres i fastapi.
version: '3.8'
services:
postgres:
image: postgres:16.1-alpine3.19
command: postgres -c log_statement=all
volumes:
- postgres_volume:/var/lib/postgresql/data
networks:
- private-network
ports:
- "5433:5432"
env_file:
- ./.env
fastapi:
build:
dockerfile: ./docker/fastapi/Dockerfile
context: .
args:
USER_UID: ${USER_UID:-1000}
USER_GID: ${USER_GID:-1000}
depends_on:
- postgres
command: ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080", "--reload"]
networks:
- private-network
ports:
- "8081:8080"
env_file:
- ./.env
volumes:
- ./app:/app
volumes:
postgres_volume:
networks:
private-network:
driver: bridge
Wartym zwrócenia uwagi jest to, że także obraz z Postgresem jest w lekkiej wersji Alpine.
Komenda postgres -c log_statement=all Nadpisuje domyślną komendę uruchamiającą PostgreSQL. Przekazany parametr instruuje bazę danych aby logowała wszystkie wykonane polecenia SQL. Ułatwia to debugowanie.
Baza jest otwarta na połączenia z zewnątrz na porcie 5433. Do działania aplikacji FastAPI nie jest to potrzebne gdyż kontener z aplikacją łączy się z bazą danych po sieci wewnętrznej, ale pozwoli na połączenie się z PostgreSQL z zewnętrznym klientem w celu bezpośredniego i wygodnego przeglądania danych.
Serwis fastapi jest budowany w oparciu o rozszerzony obraz Pythona w wersji 3.12 - co zostało omówione wyżej - i zależy on od serwisu postgres. Opcja depends_on nie gwarantuje, że serwis, od którego zależy inny serwis, jest "w pełni gotowy" do pracy (np. że baza danych zaakceptuje połączenia) przed uruchomieniem zależnego serwisu. Zapewnia jedynie, że kontener z bazą danych zostanie uruchomiony przed rozpoczęciem uruchamiania kontenera z aplikacją. W tym przypadku powinno to wystarczyć, ale w niektórych scenariuszach może być konieczne użycie skryptów startowych lub "zdrowotnych" mechanizmów kontroli (health checks) w aplikacjach, aby upewnić się, że zależności - w tym wypadku Postgres - są w pełni gotowe do działania.
Polecenie command: ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8080", "--reload"] wskazuje jak uruchomić serwowaną przez kontener aplikację i składa się jakby z kilku części.
uvicorn - Jest to serwer ASGI przeznaczony do uruchamiania aplikacji asynchronicznych w Pythonie. Uvicorn jest popularnym wyborem do obsługi aplikacji napisanych przy użyciu FastAPI, ponieważ jest lekki, szybki i wspiera asynchroniczność.
app.main:app - Określa, gdzie znajduje się aplikacja FastAPI do uruchomienia. Tutaj
app.main:appoznacza, że Uvicorn powinien zaimportować instancję aplikacji (zmiennąapp) z modułumain.py, który znajduje się w katalogu./app.--host "0.0.0.0" - Ustawia adres, na którym serwer będzie nasłuchiwał połączeń. Adres
0.0.0.0oznacza, że serwer będzie dostępny na wszystkich interfejsach sieciowych maszyny, co pozwala na łączenie się z serwerem z zewnątrz (np. z przeglądarki na komputerze hosta).--port "8080" - Określa port, na którym serwer będzie nasłuchiwał. W tym przypadku jest to port 8080. To ustawienie powinno odpowiadać mapowaniu portów zdefiniowanemu w sekcji
portsdla tego serwisu. Dla ustawienia"8081:8080"opcja ta musi pokrywać się z tym co jest po prawej stronie dwukropka - czyli numer portu używany wewnątrz kontenera. Port po prawej służy do połączenia się z zewnątrz, czyli chcąc się dostać do aplikacji z przeglądarki internetowej trzeba użyć adresulocalhost:8081.--reload - Ta opcja powoduje, że serwer będzie automatycznie restartował się przy każdej zmianie w kodzie aplikacji. Jest to bardzo użyteczne podczas rozwoju aplikacji, gdyż nie wymaga ręcznego restartowania serwera przy każdej modyfikacji kodu. Należy jednak pamiętać, że użycie tej opcji w środowisku produkcyjnym nie jest zalecane, ponieważ może wprowadzać niestabilność.
Plik .env jako sposób na przechowywanie danych wrażliwych i zapewnienie elastyczności konfiguracji
Oba serwisy czytają zmienne środowiskowe z pliku .env. Zawiera on dane wrażliwe jak hasła, tokeny itp lub też zmienne konfiguracyjne zależne od środowiska - inne dla środowiska lokalnego, testowego, developerskiego, staging-u czy produkcji. Ze względów bezpieczeństwa, ale też praktyczny plik ten nie jest trzymany w repozytorium. Zamiast niego w git przechowywany jest szablon, który zawiera wszystkie nazwy zmiennych, które należy ustawić i ich przykładowe wartości, ewentualnie wartości domyślne ale tylko dla zmiennych, które nie są wrażliwe. Jest to praktyczna realizacja trzeciej z 12 zasad metodologi Twelve-factor app odnoszącej się do konfiguracji, aplikacji przenośnych, skalowalnych i łatwych w utrzymaniu.
Plik .env.template w tym przypadku prezentuje się następująco.
# Check current user ID calling `id -u` and group ID calling `id -g`
# --------------------------------------------------------------------
USER_UID=1000
USER_GID=1000
# Environement
# --------------------------------------------------------------------
PROJECT_ENV=dev
DEBUG=1
# PostgreSQL
# --------------------------------------------------------------------
POSTGRES_DB=dbname
POSTGRES_USER=CHANGE_ME
POSTGRES_PASSWORD=CHANGE_ME
POSTGRES_HOST=postgres
POSTGRES_PORT=5432
Komendy id -u i id -g służą do sprawdzenia id lokalnego użytkownika i grupy.
Konfiguracja aplikacji FastAPI z użyciem Pydantic Settings
Jak wskazuje entrypoint serwisu fastapi - czyli wyżej omówione polecenie uruchamiające aplikację - głównym jej plikiem jest ./app/main.py. (kształt pliku się już nie zmieni a zakomentowane fragmenty kodu zostaną odkomentowane w dalszej części artykułu)
from fastapi import FastAPI
from app.api.v1 import (
# example,
ping,
)
app = FastAPI()
# app.include_router(example.router)
app.include_router(ping.router)
Została tu zdefiniowana aplikacja app, do której został podpięty m.in. pierwszy endpoint zaimportowany z pliku ./app/api/v1/ping.py
from fastapi import APIRouter, Depends
from app.core.config import Settings, get_settings
router = APIRouter(prefix="/v1/ping", tags=["Ping"])
@router.get("/")
async def ping(settings: Settings = Depends(get_settings)):
return {"pong": f"{settings.project_name} v{settings.project_version}"}
Endpoint ten po odpytaniu powinien zwrócić garść informacji pobranych z ustawień zaimportowanych z pliku konfiguracyjnego ./app/core/config.py.
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
project_name: str = "FastAPi Example Service 🔥"
project_version: str = "0.0.1"
project_env: str = "prod"
debug: bool = False
postgres_user: str
postgres_password: str
postgres_host: str = "localhost"
postgres_port: int = 5432
postgres_db: str = "fastapi_db"
test_postgres_db: str = "test_fastapi_db"
@property
def postgres_dsn(self) -> str:
return f"postgresql+asyncpg://{self.postgres_user}:{self.postgres_password}@{self.postgres_host}:{self.postgres_port}/{self.postgres_db}"
@property
def test_postgres_dsn(self) -> str:
return f"postgresql+asyncpg://{self.postgres_user}:{self.postgres_password}@{self.postgres_host}:{self.postgres_port}/{self.test_postgres_db}"
def get_settings():
return Settings()
Ustawienia zostały zaimplementowane z użyciem pydantic-settings, co daje kilka benefitów. Dziedziczenie po klasie BaseSettings umożliwia automatycznie mapowanie zmiennych środowiskowych na atrybuty klasy Settings. Zdefiniowana w pliku .env zmienna POSTGRES_USER jest w trakcie tworzenia instancji przypisywana jest do atrybutu postgres_user. Pydantic przekształci zmienną z wielkich liter na małe, zwaliduje wartość zgodnie z określonym typowaniem, a jeśli nie znajdzie oczekiwanej zmiennej środowiskowej ustawi wartość domyślną, jeśli ją określono tak jak w przypadku postgres_port.
Aby móc skorzystać z dobrodziejstw używanego w FastAPI mechanizmu zależności, dostęp do ustawień realizowany jest za pośrednictwem funkcji get_settings.
Uruchomienie projektu i odpytanie pierwszego endpointa aplikacji FastAPI
Ta minimalna konfiguracja pozwala już na uruchomienie kontenerów Docker-a.
docker compose up
i sprawdzenie działania aplikacji
Po odpytaniu np. za pomocą curl-a punktu końcowego (endpointa) ping:
curl -X 'GET' \
'http://localhost:8081/v1/ping/' \
-H 'accept: application/json'
lub też po odwiedzeniu strony, z automatycznie wygenerowaną dla API dokumentacją
SQLAlchemy i Alembic w asynchronicznych aplikacjach FastAPI
Do tej pory - choć kontener z Postgres-em został uruchomiony serwis ten nie był w żaden sposób używany. Nadszedł więc czas na skonfigurowanie połączenia z bazą danych. Nim to jednak nastąpi ułatwieniem będzie zapoznanie się ze strukturą plików omawianą w tej części artykułu. Interesować nas będą katalogi (w wymienionej kolejności):
./app/core/db./app/models/./app/alembic
W szczegółach prezentuje się to następująco
project/
├── app/
│ ├── alembic/
│ │ ├── versions/
│ │ ├── env.py
│ │ └── script.py.mako
│ ├── api/
│ ├── core/
│ │ ├── __init__.py
│ │ ├── db/
│ │ │ ├── __init__.py
│ │ │ ├── base_class.py
│ │ │ └── session.py
│ │ └── config.py
│ ├── models/
│ │ ├── __init__.py
│ │ └── example.py
│ ├── __init__.py
│ ├── alembic.ini
│ └── main.py
├── docker/
├── docker-compose.yml
└── ...
Async SQLAlchemy jako sposób na asynchroniczne połączenie z PostgreSQL
Planowany rozwój aplikacji zakłada użycie funkcji asynchronicznych, dlatego konfigurując połączenie trzeba zadbać aby nie blokowało ono ich działania. Na szczęście popularny ORM jakim jest SQLAlchemy umożliwia także pracę w trybie asynchronicznym. Z tego też powodu w zainstalowanych zależnościach znalazło się sqlalchemy[asyncio], a zamiast pakietu psycopypg, do połączenia z Postgres został użyty asyncpg. Zmianę tę odzwierciedla Postgres DSN (Data Source Name)
postgresql+asyncpg://<user>:<password>@<host>:<port>/<db>
użyty w pliku ./app/core/db/session.py do utworzenia silnika bazy danych, a przekazany za pośrednictwem zmiennej konfiguracyjnej postgres_dsn
from fastapi import Depends
from sqlalchemy.ext.asyncio import AsyncSession, create_async_engine
from sqlalchemy.orm import sessionmaker
from app.core.config import Settings, get_settings
def get_engine(settings):
params = {}
if settings.debug:
params["echo"] = True
return create_async_engine(settings.postgres_dsn, **params)
def get_session_maker(settings: Settings = Depends(get_settings)):
return sessionmaker(
bind=get_engine(settings), class_=AsyncSession, autocommit=False, autoflush=False, expire_on_commit=False
)
async def get_db(session_maker=Depends(get_session_maker)) -> AsyncSession:
async with session_maker() as db:
try:
yield db
finally:
await db.close()
Funkcja get_engine tworzy silnik bazy danych za pomocą łańcucha połączenia z ustawień aplikacji (settings.postgres_dsn). Flaga echo=True oznacza, że SQLAlchemy będzie logować wszystkie wykonane instrukcje SQL do standardowego wyjścia, co jest pomocne podczas debugowania. Ustawienie tej flagi uzależnione jest od zmiennej konfiguracyjnej debug.
Funkcja get_session_maker konfiguruje i zwraca fabrykę sesji opartą o silnik bazy danych tworzony przez get_engine. Sesje są asynchroniczne, a transakcje muszą być jawnie zatwierdzane co daje pełną kontrolę nad przebiegiem transakcji podobnie jak ustawienie opcji autoflush na false.
Uwaga
Autoflush pomaga utrzymać spójność danych i eliminuje potrzebę ręcznego zarządzania wieloma wywołaniami flush, szczególnie w złożonych transakcjach i interakcjach. Z drugiej jednak strony autoflush może wprowadzać nieoczekiwane opóźnienia, gdy "spłukiwanie" (czyli aktualizowanie stanu bazy danych zanim jeszcze nastąpi zatwierdzenie transakcji) jest wykonywane w nieoptymalnych momentach. Ponadto, gdy autoflush wywołuje wyjątki związane z naruszeniem integralności bazy danych, może to być trudniejsze do zdiagnozowania i obsługi, ponieważ błąd może pojawić się przed rzeczywistym wywołaniem metody commit.
Z kolei opcja expire_on_commit=False sprawia, że obiekty nie będą automatycznie wygaszane (odłączane od sesji) po zatwierdzeniu, co oznacza, że pozostają użyteczne po zatwierdzeniu transakcji.
Ostatnia z utworzonych instrukcji get_db to asynchroniczny menedżer kontekstu zaprojektowany do użycia z systemem wstrzykiwania zależności FastAPI. Gdy endpoint będzie wymagać sesji bazy danych, to właśnie ta funkcja będzie używana do jej dostarczenia.
Modele SQLAlchemy w FastAPI
Plik ./app/core/db/base_class.py zawiera jedynie kilka linijek kodu, który będzie jednak importowany w wielu częściach projektu.
from sqlalchemy.orm import declarative_base
Base = declarative_base()
W tym krótkim fragmencie kodu tworzona jest klasa bazowa, z której będą dziedziczyć wszystkie modele danych w aplikacji. Klasy utworzone na podstawie tej klasy bazowej będą automatycznie posiadać metadane (informacje o strukturze bazy danych, takie jak tabele i ich kolumny), które SQLAlchemy używa do mapowania obiektów Python na wpisy w bazie danych. Przykładem takiego modelu jest model Example przedstawiony w pliku ./app/models/example.py
from sqlalchemy import Column, Integer, String
from app.core.db import Base
class Example(Base):
__tablename__ = "examples"
id = Column(Integer, primary_key=True, index=True)
name = Column(String)
Gdy aplikacja jest uruchamiana, SQLAlchemy wykorzystuje informacje z klasy bazowej Base oraz z klas dziedziczących, aby zarządzać bazą danych. Może automatycznie tworzyć tabelki, zarządzać relacjami między nimi, oraz wykonywać operacje takie jak zapytania, dodawanie rekordów, usuwanie, itp. Dzięki temu możliwe jest automatyczne utworzenie schematu bazy danych lub też zaprzęgnięcie do tego celu Alembica.
Ponieważ jak już wspomniano Base model i funkcja get_db będą najczęściej używane w różnych częściach kodu można pokusić się o skrócenie ścieżki ich importu poprzez dodanie do pliku ./app/core/db/__init__.py
from .base_class import Base
from .session import get_db
__all__ = ["Base", "get_db"]
Migracje Alembic z Async SQLAlchemy
Inicjalizacja migracji alembic dla połączeń asynchronicznych (opcja -t async) powinna nastąpić z poziomu kontenera Dockera.
docker compose run --rm fastapi \
alembic init -t async alembic
Spowoduje to wygenerowanie w katalogu ./app następujących plików i katalogów
app/
├── alembic
│ ├── README
│ ├── env.py
│ ├── script.py.mako
│ └── versions
└── alembic.ini
Plik ./app/alembic.ini zawiera konfigurację, ./app/alembic/script.py.mako jest szablonem, na bazie którego będą następnie generowane w katalogu ./app/alembic/versions już konkretne pliki migracji.
Aby zintegrować Alembica z projektem koniecznym będzie wprowadzenie zmian w pliku ./app/alembic/env.py, służącym do uruchamiania wszelkich operacji związanych z migracjami. Dla skrócenia przytaczanego kodu usunięto z niego wszelkie komentarze poza tymi wskazującymi na dodane lub zmodyfikowane linie kodu.
import asyncio
from logging.config import fileConfig
from app.core.config import settings # added
from app.core.db import Base # added
from sqlalchemy import pool
from sqlalchemy.engine import Connection
from sqlalchemy.ext.asyncio import async_engine_from_config
from alembic import context
config = context.config
config.set_main_option(
"sqlalchemy.url", settings.postgres_dsn # modified
)
if config.config_file_name is not None:
fileConfig(config.config_file_name)
target_metadata = Base.metadata # modified
def run_migrations_offline() -> None:
url = config.get_main_option("sqlalchemy.url")
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def do_run_migrations(connection: Connection) -> None:
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
async def run_async_migrations() -> None:
connectable = async_engine_from_config(
config.get_section(config.config_ini_section, {}),
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
async with connectable.connect() as connection:
await connection.run_sync(do_run_migrations)
await connectable.dispose()
def run_migrations_online() -> None:
asyncio.run(run_async_migrations())
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()
Kodu wygenerowanego nie będę omawiał natomiast wprowadzone zmiany służą przekazaniu do Alembic-a połączenia do bazy danych oraz informacji o zdefiniowanych modelach, które pobierane są z metadanych modelu bazowego Base opisywanego kilka akapitów wyżej.
Generowanie pierwszej migracji wygląda następująco:
docker compose run --rm fastapi \
alembic revision --autogenerate -m 'Creating table examples'
Zostanie wygenerowana migracja w pliku, którego nazwa będzie zbliżona do ./app/alembic/versions/84cb00c03089_creating_table_examples.py
"""Creating table examples
Revision ID: 84cb00c03089
Revises:
Create Date: 2024-04-07 16:34:43.353010
"""
from collections.abc import Sequence
import sqlalchemy as sa
from alembic import op
# revision identifiers, used by Alembic.
revision: str = "84cb00c03089"
down_revision: str | None = None
branch_labels: str | Sequence[str] | None = None
depends_on: str | Sequence[str] | None = None
def upgrade() -> None:
# ### commands auto generated by Alembic - please adjust! ###
op.create_table(
"examples",
sa.Column("id", sa.Integer(), nullable=False),
sa.Column("name", sa.String(), nullable=True),
sa.PrimaryKeyConstraint("id"),
)
op.create_index(op.f("ix_examples_id"), "examples", ["id"], unique=False)
# ### end Alembic commands ###
def downgrade() -> None:
# ### commands auto generated by Alembic - please adjust! ###
op.drop_index(op.f("ix_examples_id"), table_name="examples")
op.drop_table("examples")
# ### end Alembic commands ###
Wygenerowana migracja zawiera zarówno kod wprowadzający zmiany (funkcja upgrade), jak i służący do ich wycofania (funkcja downgrade) gdyby zaszła taka potrzeba.
Wdrożenie migracji wymaga wywołania komendy
docker comopose run --rm fastapi \
alembic upgrade head
Asynchroniczne endpointy w FastAPI
Mając zdefiniowany i wdrożony model oraz metodę na połączenie z bazą danych przyszła pora na dodanie kilku asynchronicznych endpointów, które pozwolą zademonstrować jak w praktyce zaimplementować funkcjonalne, asynchroniczne API REST-owe. W tym celu zostaną dodane wyżej wspomniane punkty końcowe, ale też metody CRUD pozwalające na zapis, odczyt, modyfikację i usunięcie danych z bazy danych oraz serializery Pydantic służące do walidacji i formatowania danych. Na zaktualizowanym poniżej schemacie struktury projektu rozwinięte pozostały jedynie te katalogi, w których pojawiły się nowe pliki omawiane w tej części artykułu.
project/
├── app/
│ ├── alembic/
│ ├── api/
│ │ ├── v1/
│ │ │ ├── __init__.py
│ │ │ ├── example.py
│ │ │ └── ping.py
│ │ └── __init__.py
│ ├── core/
│ ├── crud/
│ │ ├── __init__.py
│ │ └── example.py
│ ├── models/
│ ├── schemas/
│ │ ├── __init__.py
│ │ └── example.py
│ ├── __init__.py
│ ├── alembic.ini
│ └── main.py
├── docker/
├── docker-compose.yml
└── ...
Jak widać na powyższym schemacie zostało dodane kilka nowych katalogów, które porządkują pliki według funkcji, które będą realizować. Taki kształt hierarchii plików sprawdza się w niewielkich projektach lub wręcz mikroserwisach, dla bardziej rozbudowanych implementacji zapewne lepszym byłoby przyjęcie bardziej dopasowanej do projektu organizacji plików i katalogów.
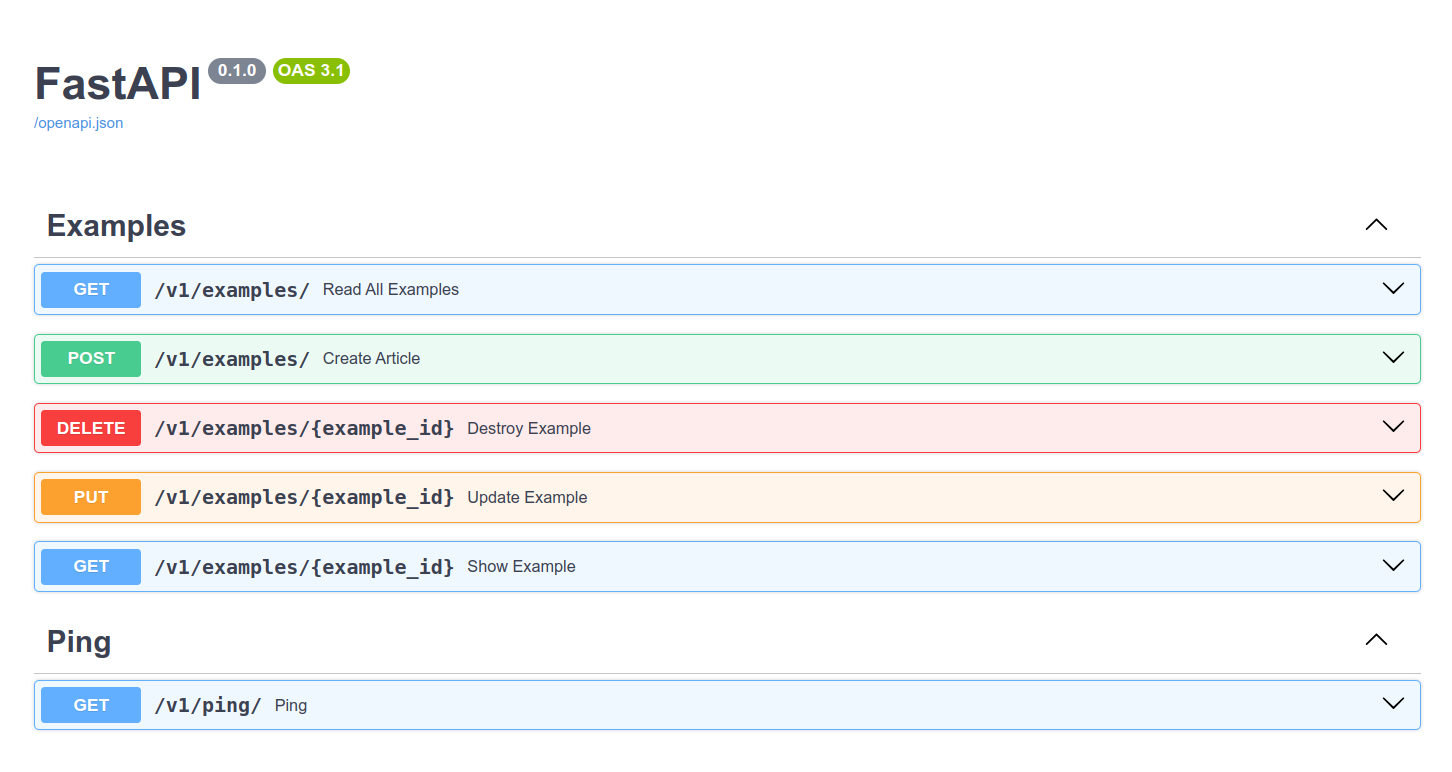
Adresy punktów końcowych realizowane przez system routingu FastAPI
W pliku ./app/api/v1/example.py zostały zdefiniowane funkcje widoków definiujące punkty końcowe - z angielskiego endpointy.
from fastapi import APIRouter, Depends, HTTPException, status
from sqlalchemy.ext.asyncio import AsyncSession
from app.core.db import get_db
from app.crud.example import (
create_example,
get_all_examples,
get_and_delete_example,
get_and_update_example,
get_example,
)
from app.schemas.example import ExampleInpt, ExampleOut
router = APIRouter(prefix="/v1/examples", tags=["Examples"])
@router.get("/", response_model=list[ExampleOut])
async def read_all_examples(db: AsyncSession = Depends(get_db)):
return await get_all_examples(db)
@router.post("/", status_code=status.HTTP_201_CREATED)
async def create_article(request: ExampleInpt, db: AsyncSession = Depends(get_db)):
return await create_example(request, db)
@router.delete("/{example_id}", status_code=status.HTTP_204_NO_CONTENT)
async def destroy_example(example_id: int, db: AsyncSession = Depends(get_db)):
try:
await get_and_delete_example(example_id, db)
except ValueError as e:
raise HTTPException(status_code=status.HTTP_404_NOT_FOUND, detail=str(e))
@router.put("/{example_id}", status_code=status.HTTP_200_OK, response_model=ExampleOut)
async def update_example(example_id: int, request: ExampleInpt, db: AsyncSession = Depends(get_db)):
try:
return await get_and_update_example(example_id, request, db)
except ValueError as e:
raise HTTPException(status_code=status.HTTP_404_NOT_FOUND, detail=str(e))
@router.get("/{example_id}", status_code=status.HTTP_200_OK, response_model=ExampleOut)
async def show_example(example_id: int, db: AsyncSession = Depends(get_db)):
try:
return await get_example(example_id, db)
except ValueError as e:
raise HTTPException(status_code=status.HTTP_404_NOT_FOUND, detail=str(e))
W konfiguracji routera APIRouter określono prefiks ścieżki /v1/examples co oznacza, że wszystkie trasy endpointów udekorowanych tym routerem będą zaczynały się tak samo, a kończyły się w zależności od tego jak wygląda dalsza ścieżka definiowana już specyficznie dla poszczególnych endpointów.
W efekcie:
@router.get("/" ...)da adreshttp://localhost:8081/v1/example/a
@router.get("/{example_id}" ...)utworzy adreshttp://localhost:8081/v1/example/{example_id}
Metody HTTP w routingu FastAPI
[[REST API - MDD#Czasowniki HTTP a operacje REST API|Zgodnie z zasadami REST API, w zależności od rodzaju operacji realizowanej przez dany endpoint używane są różne metody HTTP.]] Do utworzenia obiektu wykorzystywana jest metoda HTTP POST, do modyfikacji PUT, do usuwania obiektu DELETE a do pobrania listy obiektów, jak i pojedynczego obiektu metoda GET.
Statusy odpowiedzi w REST-owym API FastAPI
Podobnie ze statusami odpowiedzi. W REST API kod statusu odpowiedzi informuje o powodzeniu przeprowadzonej operacji lub też o wystąpieniu błędu i jego rodzaju. I ponownie. Funkcja widoku tworząca zasób, w przypadku powodzenia - obok danych utworzonego obiektu - powinna zwracać status 201, a w przypadku modyfikacji czy pobrania zasobu status 200. Z kolei punkt końcowy służący do usuwania zasobu niczego nie zwraca poza statusem odpowiedzi o czym informuje sam kod 204. Jak można zaobserwować w kodzie, w pewnych okolicznościach zgłaszany jest wyjątek powodujący zwrócenie statusu 404 oznaczającego brak zasobu lub niemożność jego odnalezienia.
Zwykle kody zaczynające się od 4xx oznaczają błąd, ale nie zawsze trzeba je tak interpretować. Zauważ, że o ile w przypadku funkcji update_example podniesienie wyjątku 404 faktycznie alarmuje o niepożądanej sytuacji - w końcu nie udało się zmodyfikować obiektu bo go nie znaleziono. Ale już w kontekście działania funkcji destroy_example, kod 404 można potraktować jak powodzenie ponieważ intencją wywołania tego endpointa jest usunięcie danego zasobu, a skoro go już nie ma to też dobrze.
Walidatory i serializery Pydantic
Dane wysyłane do punktów końcowych lub też jest przez nie zwracane przybierają określony kształt i podlegają różnym restrykcjom. Z uwagi na bezpieczeństwo wszystko co wchodzi do funkcji endpointa musi zostać sprawdzone i być przesłane w określonej strukturze aby było możliwe do interpretacji. Podobnie na wyjściu. Każdy klient API spodziewa się danych w określonym formacie. FastAPI do walidacji danych i ich serializacji używa modeli Pydantic, które to struktury są importowane z pliku ./app/schemas/example.py
from pydantic import BaseModel, ConfigDict
class ExampleInpt(BaseModel):
name: str
model_config = ConfigDict(from_attributes=True)
class ExampleOut(BaseModel):
id: int
name: str
model_config = ConfigDict(from_attributes=True)
Klasa ExampleInpt reprezentuje model danych wejściowych. Jest używana przy tworzeniu nowego obiektu, dlatego też nie ma zdefiniowanego pola id ponieważ tworzeniem identyfikatora zasobu zajmuje się baza danych. Anotacja Pythona str ułatwia określenie typu oczekiwanej wartości pola name i jest ona używana przez Pydantica do walidacji przesłanej wartości, ale też do prawidłowej serializacji.
Obiekt po utworzeniu i zwróceniu przez bazę danych sprowadzany jest do postaci instancji klasy ExampleOut. Dzięki odpowiedniej konfiguracji modelu i ustawieniu parametru from_attributes na true możliwym jest utworzenie obiektu modelu Pydantic bezpośrednio z instancji modelu SQLAlchemy, jak to ma miejsce w każdym z endpointów ze zdefiniowanym w routerze modelem odpowiedzi (response_model=ExampleOut).
Nie ma żadnego dodatkowego przekształcenia pomiędzy funkcjami CRUD, które zwracają dane w postaci instancji modelu Example, a używanym do serializacji odpowiedzi modelem ExampleOut.
Asynchroniczne funkcje CRUD w FastAPI
Funkcje służące do manipulacji danych w bazie danych zostały zaimplementowane w pliku ./app/crud/example.py.
from sqlalchemy import select
from sqlalchemy.ext.asyncio import AsyncSession
from app.models.example import Example
from app.schemas.example import ExampleInpt
async def get_all_examples(db: AsyncSession):
result = await db.execute(select(Example))
return result.scalars().all()
async def create_example(request: ExampleInpt, db: AsyncSession, commit: bool = True) -> Example:
create_data = request.model_dump(exclude_unset=True)
new_example = Example(**create_data)
db.add(new_example)
if commit:
await db.commit()
await db.refresh(new_example)
return new_example
async def get_and_delete_example(example_id: int, db: AsyncSession, commit: bool = True) -> Example:
example = await get_example(example_id, db)
await db.delete(example)
if commit:
await db.commit()
return example
async def get_and_update_example(example_id: int, request: ExampleInpt, db: AsyncSession, commit: bool = True) -> Example:
example = await get_example(example_id, db)
update_data = request.model_dump(exclude_unset=True)
for key, value in update_data.items():
setattr(example, key, value)
if commit:
await db.commit()
await db.refresh(example)
return example
async def get_example(example_id: int, db: AsyncSession) -> Example:
result = await db.execute(select(Example).filter(Example.id == example_id))
example = result.scalars().first()
if not example:
raise ValueError(f"Example with the id {example_id} not found")
return example
Nie są to standardowe funkcje CRUD (Create, Read, Update, Delete). Realizują one te podstawowe funkcjonalności ale z uwagi na potrzebę zapewnienia dodatkowych informacji - szczególnie - funkcje odpowiedzialne za modyfikację i usuwanie zasobów zostały nieco rozbudowane. Najpierw obiekt jest pobierany, a później modyfikowany lub usuwany. Pozwala to na zgłoszenie wyjątku w sytuacji braku zasobu. W innym przypadku nie bylibyśmy w stanie stwierdzić czy aktualizacja zasobu lub jego usunięcie faktycznie się odbyło bo baza danych nie zgłosiłaby żadnego wyjątku. W rzeczywistości, rzadko mamy do czynienia ze "sterylną" implementacją CRUD-a a powyższy przykład, choć jedynie w celach demonstracyjnych jest jednak dobrą i praktyczną egzemplifikacją.
Wdrożenie transakcji bazodanowych w asynchronicznych funkcjach CRUD w FastAPI
Funkcje modyfikujące stan bazy danych mają wdrożoną możliwość przejęcia kontroli nad chwilą zatwierdzenia zmian (commit: bool = True). Domyślnie każda zmiana jest natychmiast zatwierdzana, ale gdybyśmy chcieli wykonać kilka instrukcji w ramach pojedynczego wywołania endpointu i objąć je wszystkie transakcją, jesteśmy w stanie to zrobić. Wszystkie funkcje realizujące zapytania SQL modyfikujące stan bazy danych zostały by wywołane z atrybutem commit=False i tylko ostatnia operacja w transakcji zatwierdzałaby zmiany.
Dynamiczne rozwiązywanie i wstrzykiwanie zależności w funkcje frameworka FastAPI
Każda z funkcji operujących na bazie danych wymaga połączenia z bazą danych. Obiekt sesji bazy danych jest wstrzykiwany do funkcji widoku przy użyciu klasy Depends(get_db) i przekazywany do funkcji CRUD za pośrednictwem zmiennej db: AsyncSession.
Mechanizm wstrzykiwania zależności zastosowany w FastAPI jest elastyczny a jego użycie nie ogranicza nas jedynie do funkcji definiujących endpointy. Z drugiej jednak strony użycie Depends poza funkcjami widoków nie jest intuicyjne i nastręcza pewnych problemów choćby z testowaniem ich poza kontekstem aplikacji fastapi.
Na koniec należy przypomnieć o zakomentowanym fragmencie kodu w pliku ./app/main.py, którego odkomentowanie jest niezbędne aby zarejestrować nowo dodane endpointy.
Podsumowanie
W artykule przedstawiono kompleksowy proces konfiguracji projektu opartego na frameworku FastAPI, bazie danych PostgreSQL i kontenerach Docker. Pokazano, jak stworzyć strukturę katalogów i pliki konfiguracyjne dla FastAPI i SQLAlchemy, zdefiniować modele bazy danych oraz skonfigurować asynchroniczne połączenie z bazą PostgreSQL. Omówiono także integrację narzędzia Alembic do zarządzania migracjami bazy danych. Ostatnia część artykułu skupiła się na implementacji asynchronicznych endpointów w FastAPI, wykorzystujących zależności do obsługi sesji bazy danych. Zostały omówione dobre praktyki definiowania ścieżek, walidacji i serializacji danych przy użyciu Pydantic. A wszystko to w celu ułatwienia implementacji nowoczesnych aplikacji internetowych opartych na mikroserwisach.