Agregacja logów Docker w ELK (Logstash, Elasticsearch, Kibana) w wersji 8.x
Grudzień 26, 2023 | #docker , #elk
011111
010001
101101
Co to jest ELK Stack (Elastic Stack)
ELK Stack, znany również jako Elastic Stack, to popularna kombinacja trzech projektów open-source: Elasticsearch, Logstash i Kibana, które współpracują, aby zapewnić potężne narzędzie do wyszukiwania, analizy i wizualizacji danych. Każdy z tych komponentów pełni specyficzną rolę:
Logstash: To serwer przetwarzania danych, który agreguje, przetwarza i przekształca dane z różnych źródeł, a następnie przesyła je do Elasticsearch. Logstash może przetwarzać logi, strumienie danych i inne rodzaje informacji z różnych źródeł, takich jak systemy plików, bazy danych, logi aplikacji itp.
Elasticsearch: Jest to wyszukiwarka i silnik analityczny oparty na Lucene. Elasticsearch jest używany do indeksowania, przechowywania i przeszukiwania dużych ilości danych w czasie rzeczywistym. Jest wysoce skalowalny, co pozwala na przechowywanie i przetwarzanie ogromnych ilości danych w sposób efektywny i szybki.
Kibana: Jest to narzędzie do wizualizacji danych i dashboardów, które łączy się z Elasticsearch. Umożliwia tworzenie graficznych przedstawień danych przechowywanych w Elasticsearch, takich jak wykresy, mapy, tabelki itp. Kibana jest używana do analizy i monitorowania danych w czasie rzeczywistym.
UWAGA!
Elastic Stack to bardziej aktualna nazwa, obejmująca również Beats – lekkie, jednozadaniowe agenty napisane w Go, które są instalowane na serwerach, urządzeniach lub w dowolnym miejscu, gdzie gromadzone są dane. Mają one za zadanie zbieranie różnych rodzajów danych i przesyłanie ich do centrum przetwarzania - najczęściej jest to Elasticsearch lub Logstash.
Elastic Beats to bardzo ciekawe uzupełnienie/rozszerzenie "świętej trójcy" elastic, ale pominiemy je w tym artykule.
Uruchomienie ELK stack na localhost w celu zbierania logów Docker-a
W dokumentacji narzędzi elastic jest dobrze opisane jak opublikować na produkcji Elasticsearch wraz z Kibana w kontenerach Docker. Mamy też informację o uruchomieniu Logstash w kontenerze Dockera. Jak te informacje zebrać do kupy i uruchomić pełen stack ELK świetnie pokazuje film Ali Younes - Install Elasticsearch Kibana and Logstash with Docker. Aby uruchomić ELK na produkcji możemy skorzystać z przytoczonej wyżej dokumentacji ale warto też zainteresować się projektem docker-elk
W moim artykule opieram się na przygotowanym przez developerów elastica gotowym pliku docker-compose.yml definiującym współpracujące ze sobą serwisy Elasticsearch i Kibana w wersji 8.x i wskazówkach Ali Younes jak dodać do tego Logstash, ale upraszczam wszystko do niezbędnego minimum pozwalającego uruchomić całość na komputerze lokalnym. Pokazuję jak skonfigurować Logstash do agregowania logów z kontenerów Docker oraz jaki wybrać sterownik logowania i co dodać do pliku docker-compose.yml przykładowego serwisu, aby jego logi trafiały do Elasticsearch i były widoczne w Kibanie.
Struktura projektu wygląda następująco
> docker_logs
> logstash / pipeline
| | logstash-docker.conf
| .env
| docker-compose.elk.yml
| docker-compose.app.yml
Na początek zdefiniujmy sobie kilka zmiennych środowiskowych
Plik .env
# Password for the 'elastic' user (at least 6 characters)
ELASTIC_PASSWORD=change-me!
# Password for the 'kibana_system' user (at least 6 characters)
KIBANA_PASSWORD=change-me!
# Version of Elastic products
STACK_VERSION=8.11.3
# Set to 'basic' or 'trial' to automatically start the 30-day trial
LICENSE=basic
# Port to expose Elasticsearch HTTP API to the host
ES_PORT=9200
# Port to expose Kibana to the host
KIBANA_PORT=5601
# Increase or decrease based on the available host memory (in bytes)
ES_MEM_LIMIT=4294967296
KB_MEM_LIMIT=1073741824
LS_MEM_LIMIT=1073741824
W pliku docker-compose.elk.yml dla uproszczenia konfiguracji na potrzeby eksperymentów na localhost - w stosunku do oryginału - usunąłem wszystko co jest związane z generowaniem certyfikatów i zdecydowałem się uruchomić tylko jednego noda z Elasticsearch więc dodałem opcję discovery.type=single-node. W związku z tym, że nie ma certyfikatów, na istnieniu których opierał się healthcheck kontenera Elasticsearch również jego musiałem zmodyfikować.
UWAGA!
Zdecydowałem się też na ograniczenie możliwego zużycia ilość pamięci heap przez JVM (Java Virtual Machine) - opcja ES_JAVA_OPTS=-Xms512m -Xmx512m. ELK stack jest wymagającym oprogramowaniem, które potrafi zgłosić wiele błędów związanych ze zużyciem pamięci. Dlatego żeby uniknąć problemów z brakiem pamięci (Out of Memory, OOM) i zabiciem procesów Docker-a sygnalizowanych kodem 137 (exit code 137) kluczowym jest właściwe dobranie wartości parametrów mem_limit oraz ulimit. Uruchamiając ELK spotkałem się też z kodem 68 (exit code 68), który w moim przypadku wiązał się z mapowaniem pamięci i koniecznością zwiększenia w systemie parametru vm.max_map_count (jest parametrem w jądrze systemu Linux, który określa maksymalną liczbę obszarów pamięci, jakie proces może mieć w swojej przestrzeni adresowej)
version: "3.8"
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:${STACK_VERSION}
volumes:
- esdata01:/usr/share/elasticsearch/data
networks:
- elk
ports:
- ${ES_PORT}:9200
environment:
- discovery.type=single-node
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- ES_JAVA_OPTS=-Xms512m -Xmx512m
mem_limit: ${ES_MEM_LIMIT}
healthcheck:
test: ["CMD-SHELL", "curl --silent --fail localhost:9200/_cluster/health || exit 1"]
interval: 10s
timeout: 10s
retries: 3
kibana:
depends_on:
es01:
condition: service_healthy
image: docker.elastic.co/kibana/kibana:${STACK_VERSION}
volumes:
- kibanadata:/usr/share/kibana/data
networks:
- elk
ports:
- ${KIBANA_PORT}:5601
environment:
- ELASTICSEARCH_HOSTS=http://es01:9200
- ELASTICSEARCH_USERNAME=kibana_system
- ELASTICSEARCH_PASSWORD=${KIBANA_PASSWORD}
- ES_JAVA_OPTS=-Xms512m -Xmx512m
mem_limit: ${KB_MEM_LIMIT}
healthcheck:
test:
[
"CMD-SHELL",
"curl -s -I http://localhost:5601 | grep -q 'HTTP/1.1 302 Found'",
]
interval: 10s
timeout: 10s
retries: 120
logstash:
depends_on:
es01:
condition: service_healthy
kibana:
condition: service_healthy
image: docker.elastic.co/logstash/logstash:${STACK_VERSION}
labels:
co.elastic.logs/module: logstash
user: root
volumes:
- logstashdata01:/user/share/logstash/data
- ./logstash/pipeline/logstash-docker.conf:/usr/share/logstash/pipeline/logstash-docker.conf:ro
environment:
- ELASTIC_USER=elastic
- ELASTIC_PASSWORD=${ELASTIC_PASSWORD}
- ELASTIC_HOSTS=http://es01:9200
- ES_JAVA_OPTS=-Xms512m -Xmx512m
command: logstash -f /usr/share/logstash/pipeline/logstash-docker.conf
networks:
- elk
ports:
- "5000:5000/tcp"
mem_limit: ${LS_MEM_LIMIT}
volumes:
esdata01:
driver: local
kibanadata:
driver: local
logstashdata01:
driver: local
networks:
elk:
driver: bridge
Plik konfiguracyjny ./logstash/pipeline/logstash-docker.conf umożliwiający zbieranie logów z kontenerów Docker-a przewiduje użycie sterownika syslog i połączenie z Logstash za pośrednictwem protokołu tcp.
Jak widać w pliku tym hasło do Elastisearch jest przekazywane za pośrednictwem zmiennej środowiskowej co jest dobrą praktyką opisaną w dokumentacji elsatic-a w artykule Secrets keystore for secure settings. Zwróć na to uwagę bo w wielu tutorialach hasło w plikach konfiguracyjnych Logstash jest podawane czystym tekstem.
Kolejną rzeczą wartą zaakcentowania jest dodanie w sekcji output parametru action => "create". Domyślnie wartością parametru action jest index. Jeśli tego nie zmienimy dane wysyłane przez Logstash nie będą się zapisywały w indeksie Elasticsearch (indeks nie zostanie utworzony), a w logach kontenera es01 zobaczymy błąd "only write ops with an op_type of create are allowed in data streams" oznaczający próbę indeksowania informacji do strumienia danych Elasticsearch, który wymaga operacji typu create.
input {
tcp {
port => 5000
type => "syslog"
}
}
filter {}
output {
elasticsearch {
index => "docker-logs-%{+YYYY.MM.dd}"
hosts => ["http://es01:9200"]
user => "elastic"
password => "${ELASTIC_PASSWORD}"
action => "create"
}
stdout { codec => rubydebug }
}
Pozostaje uruchomić ELK i - przynajmniej za pierwszym razem - obserwować co w logach piszczy
docker compose -f docker-compose.elk.yml up
Jak już wspomniałem wcześniej możemy mieć różne problemy z pamięcią - zwłaszcza na słabym komputerze lokalnym więc obserwacja zużycia pamięci też się może przydać.
docker stats
Jeśli możesz wejść na stronę Kibany pod adresem localhost:5601 i zalogować się to jesteś na dobrej drodze. Na razie jednak nie masz tu co klikać bo idneks z logami dockera zostanie utworzony dopiero jak jakieś logi zostaną do niego przesłane.
Uruchomienie aplikacji w kontenerze Docker, której logi są agregowane przez Logstash
Jeśli wszystko działa poprawnie, a kontenery Elasticsearch się nie wysypują czas uruchomić pierwszą aplikację testową generującą jakiekolwiek logi i zobaczyć czy są one zbierane przez Logstash. Ja użyłem do tego celu aplikacji Django ale nie ma znaczenia co to jest więc poniżej podaję hipotetyczny plik docker-compose.yml obrazujący jak skonfigurować logowanie.
services:
twoja_aplikacja:
image: twoj_obraz
logging:
driver: syslog
options:
syslog-address: "tcp://localhost:5000"
tag: "twoja_aplikacja"
Po uruchomieniu...
docker compose up
Zobaczyłem w konsoli następujący output.
docker compose up
[+] Building 0.0s (0/0) docker:default
[+] Running 1/0
✔ Container docker_logging-web-1 Created 0.0s
Attaching to docker_logging-web-1
docker_logging-web-1 | Watching for file changes with StatReloader
docker_logging-web-1 | Performing system checks...
docker_logging-web-1 |
docker_logging-web-1 | System check identified no issues (0 silenced).
docker_logging-web-1 |
docker_logging-web-1 | You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions.
docker_logging-web-1 | Run 'python manage.py migrate' to apply them.
docker_logging-web-1 | December 26, 2023 - 11:27:23
docker_logging-web-1 | Django version 3.2.23, using settings 'api.settings'
docker_logging-web-1 | Starting development server at http://0.0.0.0:8000/
docker_logging-web-1 | Quit the server with CONTROL-C.
Z kolei w logach Elastic Stack
docker compose -f docker-compose.elk.yml logs
zobaczyłem, że logi z mojej aplikacji Django są agregowane przez Logstash.
docker_logging-logstash-1 | {
docker_logging-logstash-1 | "type" => "syslog",
docker_logging-logstash-1 | "message" => "<30>Dec 26 12:27:23 web[160768]: Run 'python manage.py migrate' to apply them.",
docker_logging-logstash-1 | "@version" => "1",
docker_logging-logstash-1 | "event" => {
docker_logging-logstash-1 | "original" => "<30>Dec 26 12:27:23 web[160768]: Run 'python manage.py migrate' to apply them."
docker_logging-logstash-1 | },
docker_logging-logstash-1 | "@timestamp" => 2023-12-26T11:27:23.559166287Z
docker_logging-logstash-1 | }
...
Indeksowanie logów Logstash w Elasticsearch
Aby podejrzeć czy w Elasticsearch utworzył się indeks i czy zawiera jakieś dane użyjemy do tego narzędzi developerskich wbudowanych w Kibanę.
Odwiedzamy stronę localhost:5601
 Wybieramy
Wybieramy Menu -> Management -> Dev Tools
I sprawdzamy czy utworzył się indeks:
GET _cat/indices
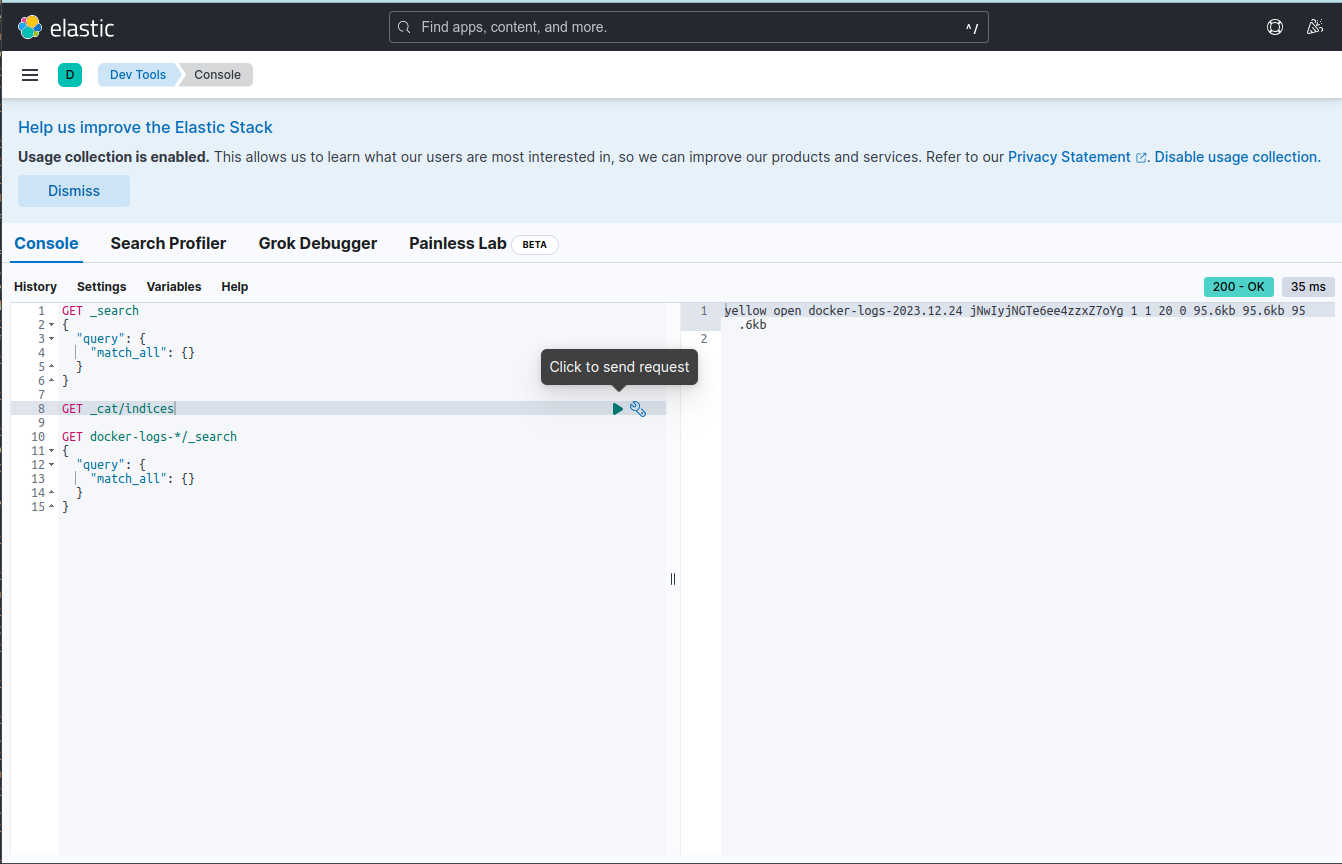
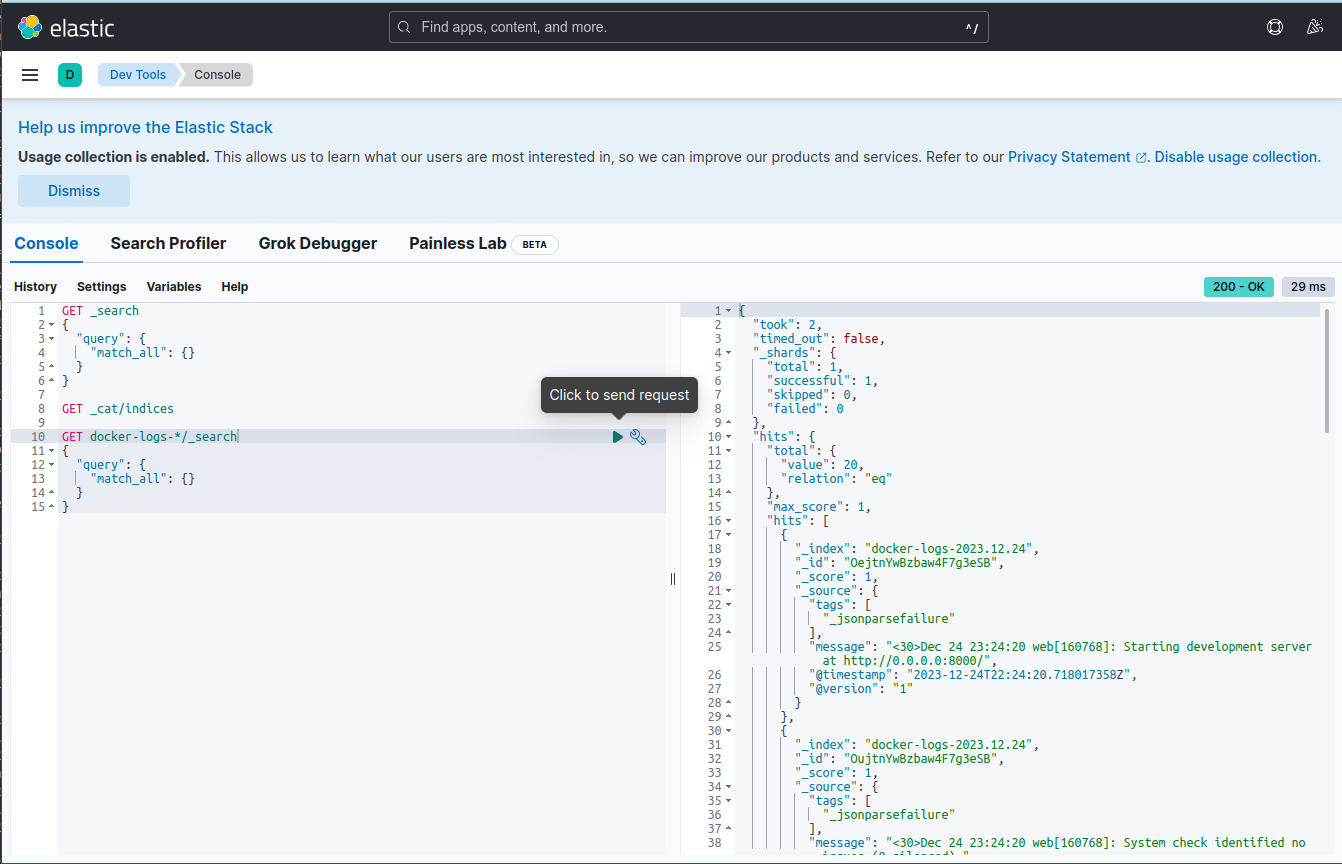
Następnie prostym zapytaniem sprawdzamy czy pierwsze logi zostały zindeksowane. dzięki temu wiemy, że Logstash uzyskał połączenie z Elasticsearch, uzyskał autoryzację i zarejestrował prawidłowo logi.
GET docker-logs-*/_search
{
"query": {
"match_all": {}
}
}
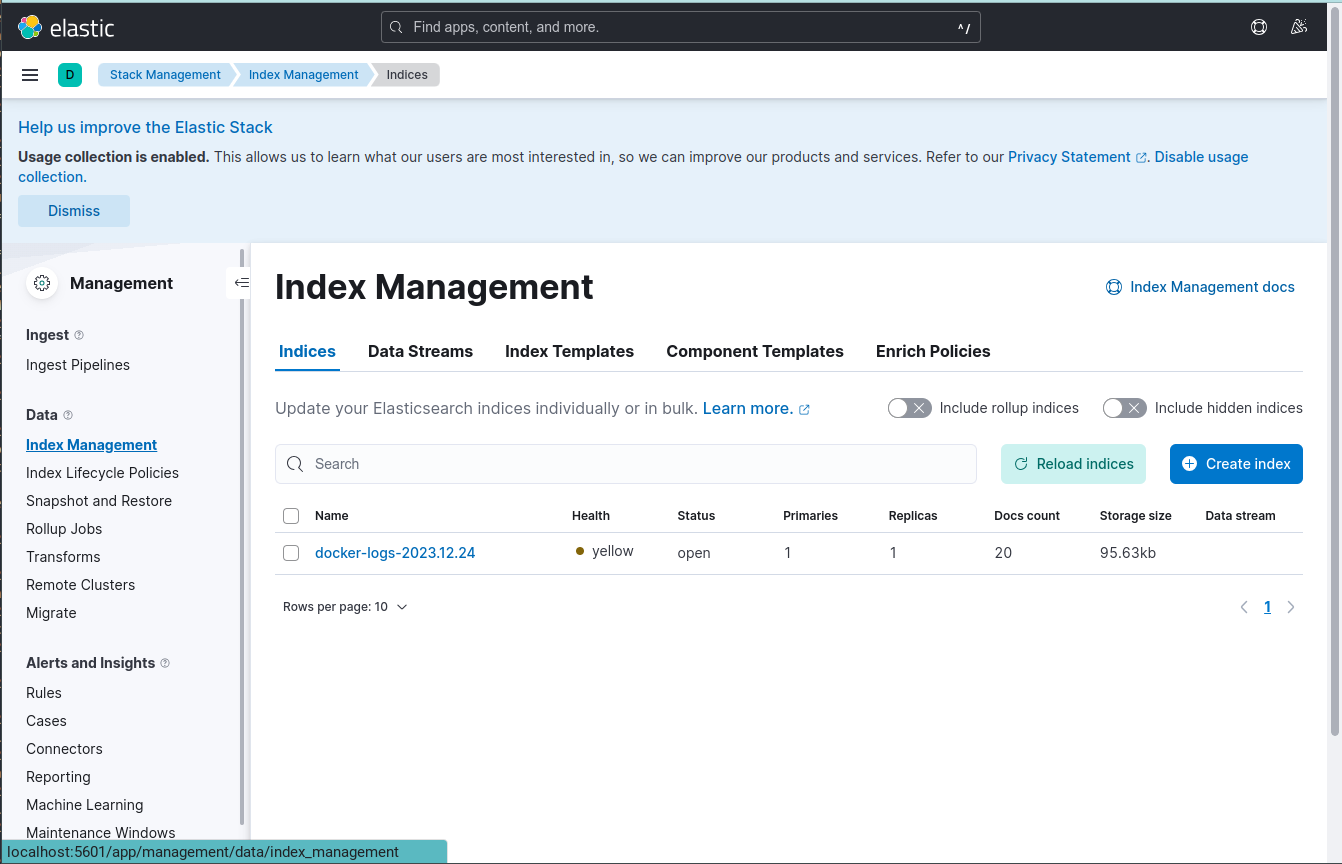
Wizualizujemy logi w Kibanie
Przechodzimy do Menu -> Management -> Stack Management
Na tej podstronie mamy podmenu, z którego wybieramy Management -> Data -> Index Management
W tym widoku upewniamy się, że w Kibanie widoczny jest indeks Elasticsearch.
Tworząc konfigurację Logstash zdefiniowaliśmy regułę, wedle której ma być tworzony indeks w Elasticsearch
index => "docker-logs-%{+YYYY.MM.dd}"
Taka definicja sprawi, że codziennie będzie tworzony nowy indeks. Ułatwia to zarządzanie indeksami i usuwanie starych logów ale sprawa też, że przeglądanie logów staje się mniej wygodne. Aby móc przeglądać logi wybierając z filtrów dowolny zakres czasowy bez skakania po poszczególnych indeksach musimy utworzyć sobie w Kibanie widok danych podając wzór według, którego agregowane będą dane z więcej niż jednego indeksu.
W tym celu w podmenu Stack Management przechodzimy do pozycji Management -> Kibana -> Data Views. (W starszych wersjach Kibany z rodziny 7.x podstrona ta nazywała się Index patterns)
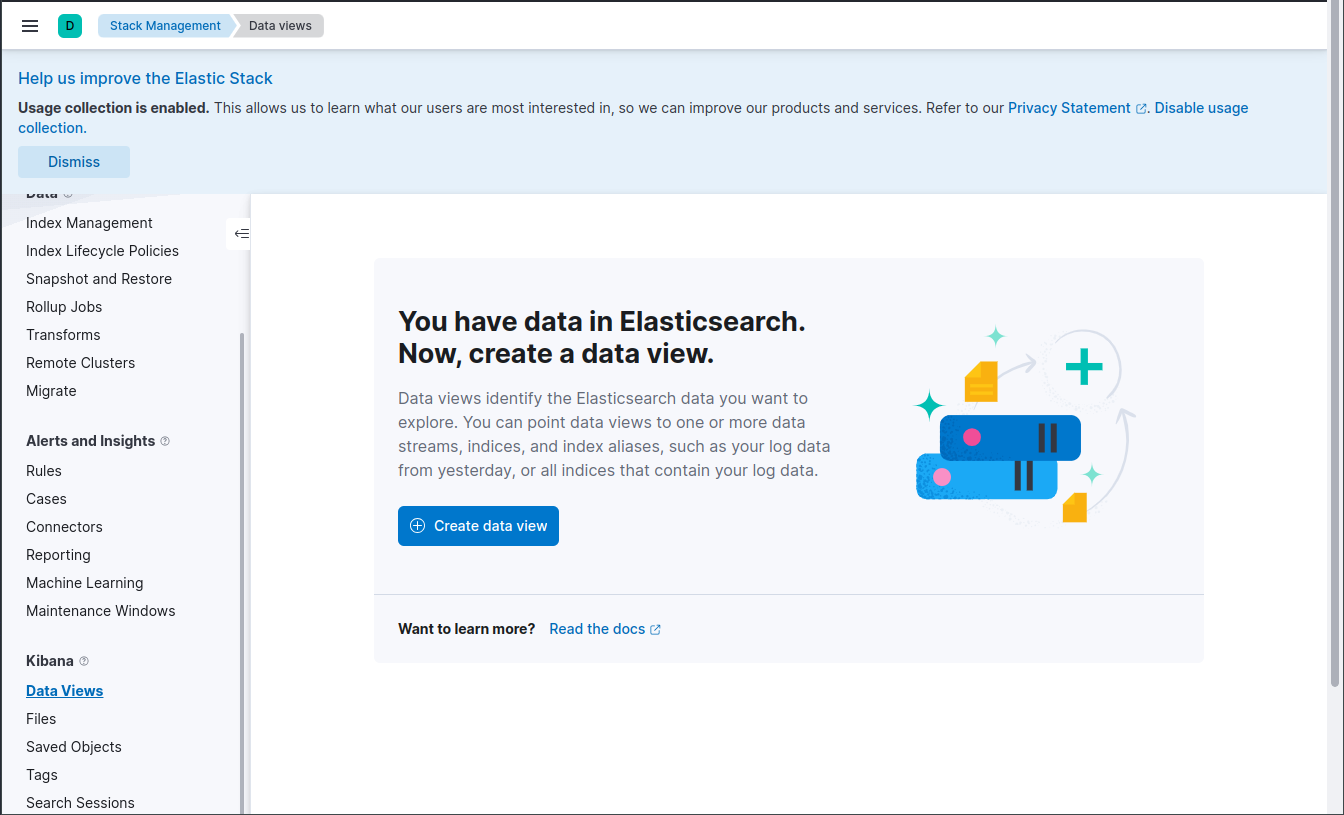
Tworzymy nowy widok podając jego nazwę, i wzór według którego wybierane będą indeksy. W Kibanie mamy podgląd dostępnych indeksów Elasticsearch - w naszym przypadku tylko jeden. Wpisując wzór od razu widzimy, które indeksy do niego pasują. Pole Timestamping field zostawiamy domyślne.
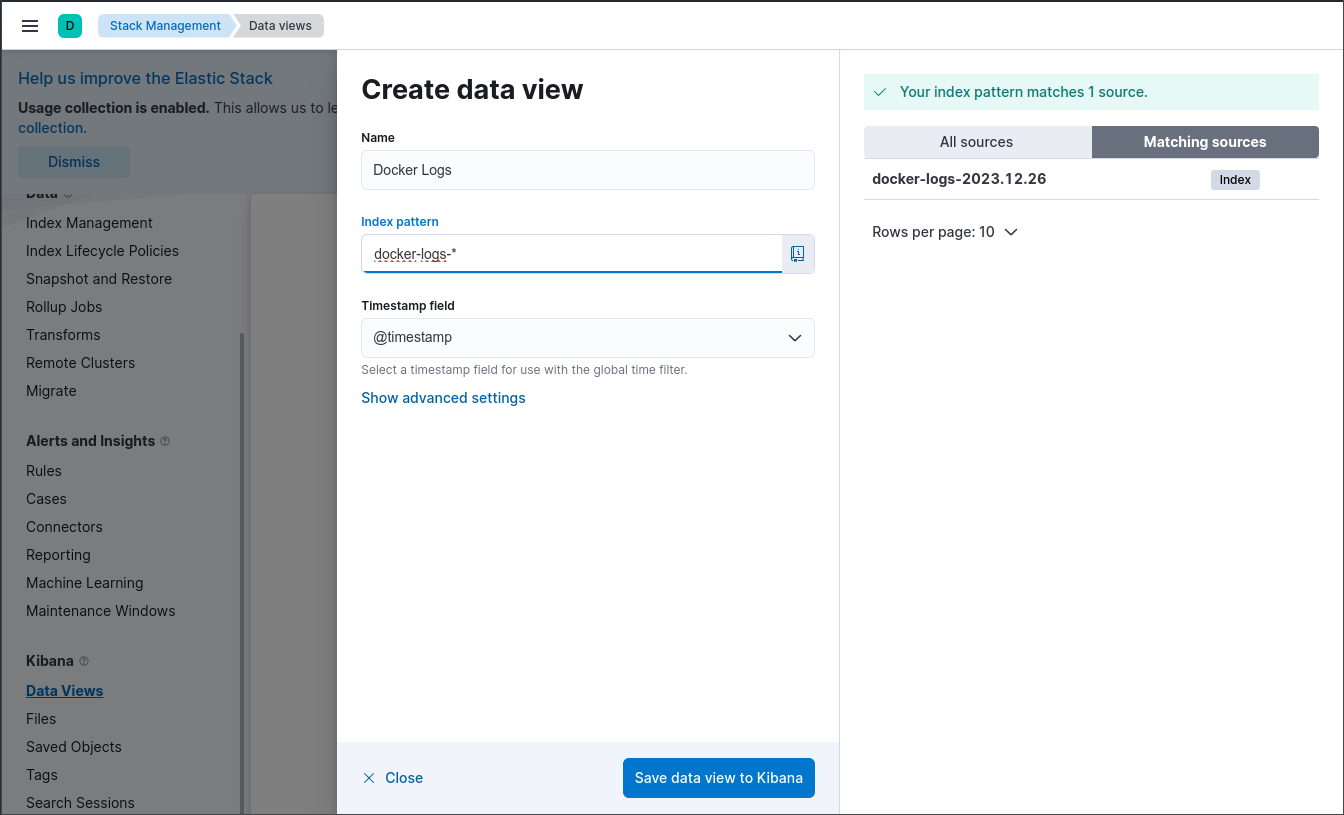
Po utworzeniu widoku widzimy z jakich pól będzie się on składał i jakie te pola mają atrybuty.
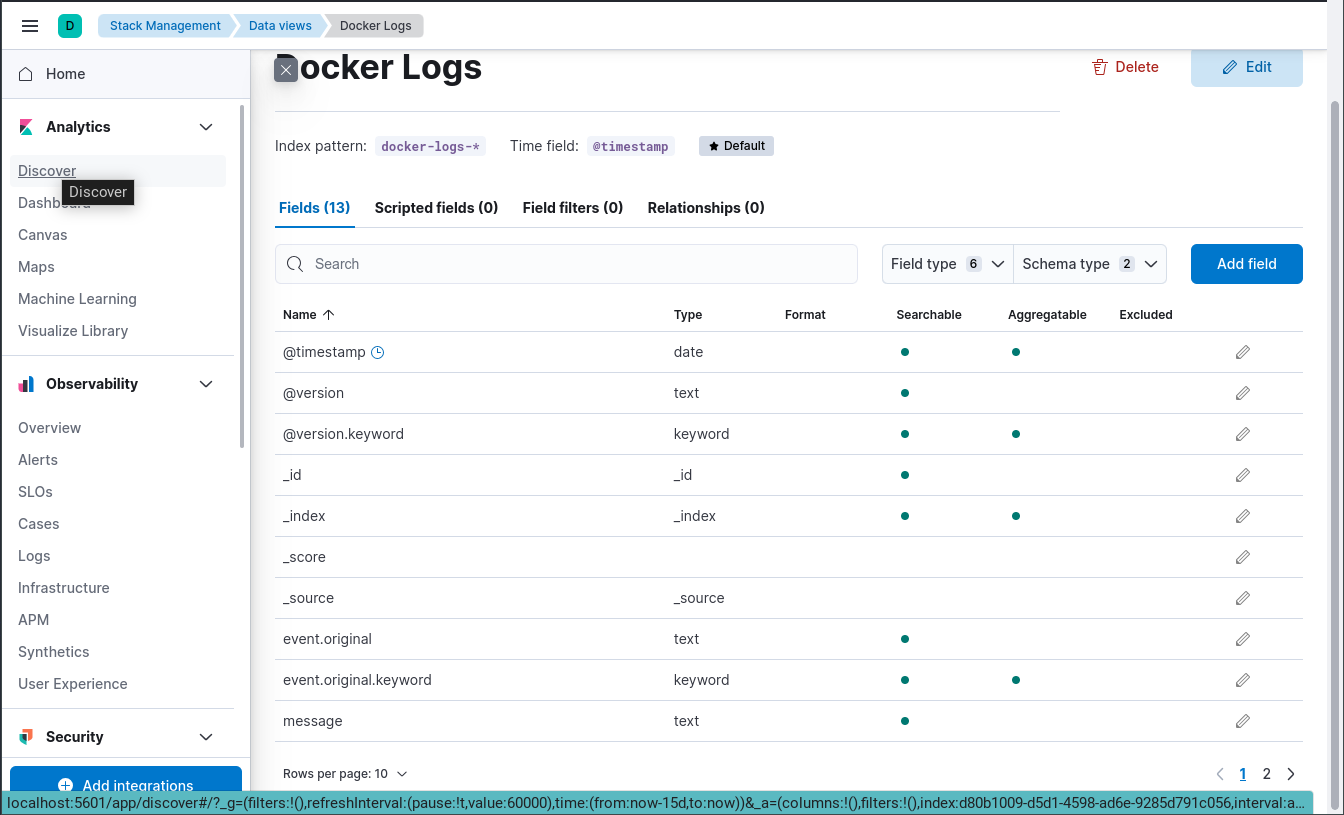
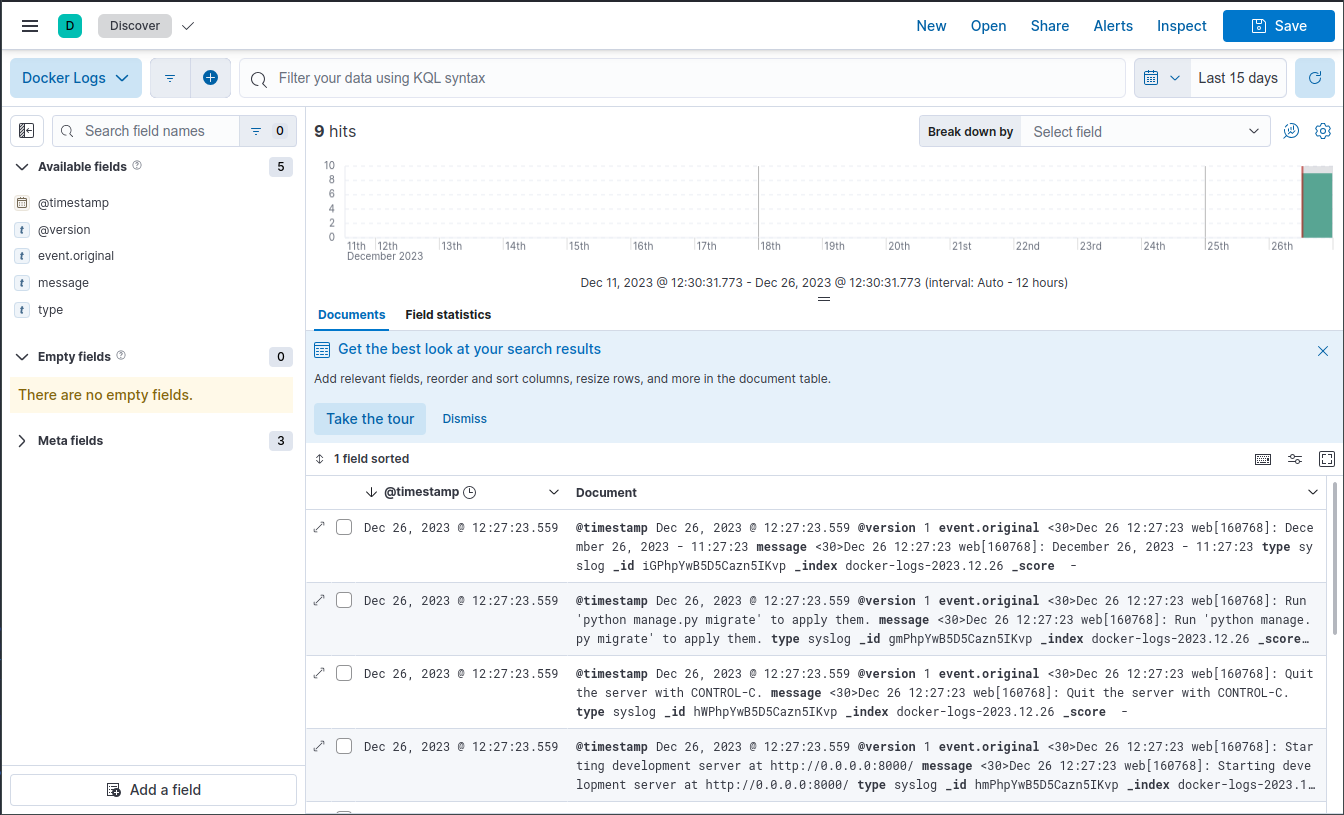
Przechodzimy do Menu -> Analytics -> Discover, a ponieważ mamy tylko jeden zdefiniowany widok, naszym oczom od razu pokazują się zarejestrowane przez Logstash logi z kontenerów Docker-a.
Alternatywy
Elastic Stack jest popularnym rozwiązaniem do zbierania, przetwarzania i analizowania dużych ilości danych, szczególnie logów. Jako popularne narzędzia open-source, ELK Stack ma dużą społeczność użytkowników i bogate zasoby dokumentacji. Elasticsearch jest bardzo skalowalny, co pozwala na efektywne przechowywanie i przeszukiwanie dużych ilości danych. Logstash oferuje szeroki zakres wtyczek do filtrowania i przetwarzania danych, co pozwala na zbieranie danych z różnorodnych źródeł i ich transformację z kolei Kibana umożliwia tworzenie zaawansowanych dashboardów i wizualizacji, co jest przydatne w analizie danych i monitoringu.
Z drugiej strony ELK może być trudny w konfiguracji i wymaga pewnej wiedzy technicznej, szczególnie przy skomplikowanych setupach. Kibana jest bardzo rozbudowana ale przez to też trudniejsza w użyciu Elasticsearch może być zasobożerny, szczególnie w przypadku dużych ilości danych i zapytań. Jest to twardy orzech do zgryzienia i warto rozważyć alternatywy a jest ich trochę:
Splunk: Potężne komercyjne rozwiązanie do monitorowania, wyszukiwania i analizy danych. Jest łatwiejsze w konfiguracji i użytkowaniu, ale może być droższe.
Graylog: Oparty na Elasticsearch, MongoDB i Scala, Graylog oferuje podobne funkcjonalności do ELK, ale z łatwiejszą w konfiguracji i zarządzaniu interfejsem.
Prometheus i Grafana: Chociaż głównie skoncentrowane na monitoringu wydajności, te narzędzia mogą być również używane do przetwarzania logów, szczególnie w połączeniu z narzędziami takimi jak Loki (od Grafany).
Fluentd i Fluent Bit: Lekkie narzędzia do zbierania i przesyłania logów, które mogą być zintegrowane z różnymi backendami, takimi jak Elasticsearch.
Datadog: Rozwiązanie SaaS zapewniające monitoring, logowanie i analizę w chmurze.
Wybór odpowiedniego stosu technologicznego zależy od konkretnych potrzeb organizacji, zasobów, które są dostępne, oraz poziomu skomplikowania wymaganego w procesie zbierania i analizy danych.